


Abstract
We suggest a universal phenomenological description for the collective access patterns in the Internet traffic dynamics both at local and wide area network levels that takes into account erratic fluctuations imposed by cooperative user behaviour. Our description is based on the superstatistical approach and leads to the q-exponential inter-session time and session size distributions that are also in perfect agreement with empirical observations. The validity of the proposed description is confirmed explicitly by the analysis of complete 10-day traffic traces from the WIDE backbone link and from the local campus area network downlink from the Internet Service Provider. Remarkably, the same functional forms have been observed in the historic access patterns from single WWW servers. The suggested approach effectively accounts for the complex interplay of both "calm" and "bursty" user access patterns within a single-model setting. It also provides average sojourn time estimates with reasonable accuracy, as indicated by the queuing system performance simulation, this way largely overcoming the failure of Poisson modelling of the Internet traffic dynamics.
Export citation and abstract BibTeX RIS
Introduction
Understanding the principles that govern the complex dynamics of network activity patterns is one of the challenges in modern statistical physics and its interdisciplinary applications. In large networks where human activity determines the traffic dynamics collective behaviour leads to seemingly erratic bursts. Nowadays the key origin of these bursts is the rapid information spreading via online messaging and social networks making communication faster and easier [1–3]. While very few pieces of information attract global attention [4,5], there are many local bursts induced by information spreading in local and/or tightly linked communities.
Taking into account the complex interplay of such bursts in the access dynamics, the aggregated traffic patterns exhibit pronounced phase transitions between the "calm" and the "bursty" modes reminiscent of those in other complex systems with self-organised criticality [6–8]. In the "calm" mode, when there is no particular dominance of interest, access patterns over relatively short time scales could be treated as random, and the overall traffic dynamics can be described to a reasonable approximation by linear models. In contrast, the introduction of a certain dominance of interest for a given community leads to the development of pronounced bursts indicated by strongly nonlinear excursions in the aggregated traffic dynamics.
In fact in the overall traffic at backbone links that connect wide area networks most of these small bursts are simply averaged out, while they remain significant on smaller scales such as local area networks or individual hosting servers. In the presence of these bursts the aggregated traffic on local nodes exhibits strongly nonlinear excursions predestinating the failure of conventional Poisson-Erlang models that assume random access patterns [9–11].
In this letter, we focus on finding a simple phenomenological model that is capable of describing the access patterns and reproducing the relevant traffic dynamics during both "calm" and "bursty" modes at different network scales. Since the properties of short-term access patterns may vary drastically, and thus the conditions of the central limit theorem are far from being met, we focus on the superstatistical approach recently suggested by Beck and Cohen [12]. Very recently, superstatistical approach has been suggested as a perspective tool to distinguish between normal and anomalous traffic dynamics [13].
Data sources and extraction methods
In our analysis, we use three data sources. The first source are the WIDE backbone link traces collected by the MAWI Working Group as a part of the WIDE project freely available online1 [14]. We focus on complete daily traces collected at the transit link of the WIDE network that connects many universities and research centres in Japan to the upstream Internet Service Provider (ISP). Representative data fragments, each containing ten complete 24-hour cycles, have been chosen for detailed analysis, including consecutive traces from 18/03/2008 until 20/03/2008, from 30/09/2009 until 02/04/2009 and from 13/04/2010 until 15/04/2010. The second data set has been collected in-house at the link between the local campus network of St. Petersburg Electrotechnical University and the upstream ISP. Similarly, ten daily data sets have been analysed, including traces from 17/03/2015 until 18/03/2015, from 16/04/2015 until 19/04/2015, and from 26/04/2016 until 29/04/2016. The third source contains historic traffic traces of single WWW servers collected in the middle 1990s at the Universities of Calgary and Saskatchewan in Canada (representing annual and semi-annual access patterns, respectively) obtained from the Internet Traffic Archive2 used in our earlier studies [15,16]. While the first two data sources have been chosen for detailed analysis, similar processing could not be performed for the historic data traces due to their drastically lower traffic density, and thus they have been used for validation purposes only.
The key quantities of interest in our analysis are the inter-session time and session size distributions. From the source data we obtained the table of the TCP packets transferred via the analysed links including arrival times, end user IPs and packet sizes. Next we sorted the packets by their end user IPs this way extracting individual access patterns associated with a single end user. Then in each individual access pattern we grouped multiple packets with arrival times separated by less than one second into a single session assuming them below typical end user reaction time. Once the inter-arrival time exceeded one second, a session break was inserted.
Each session was characterised by its starting time, number of connections and session size given by the total size of all packets transferred during this session. Finally, we combined the individual access patterns back into a single aggregated traffic trace, but now at individual access session level. The above procedure is not uncommon in traffic analysis [17], since it largely helps to exclude the effects of particular network organisation and technical solutions (protocols, routing algorithms, caching), this way allowing to focus rather on user activity related features. Accordingly, the statistical properties of the session level traces can be directly compared for the data initially collected at different network levels.
With few possible exceptions for globally oriented resources such as Google or Facebook, most network nodes/links exhibit pronounced daily trends in their traffic dynamics, indicating increased activity during working and/or evening hours and reduced activity during night hours, according to local time. One common way to deal with daily trends is to describe them separately from traffic fluctuations by a deterministic model. In the aggregated traffic data, the shape of the trend can be easily estimated by simple averaging over short time fragments taken at the same time of the day on different days [15]. Another way is to consider the traffic statistics for each such short-time fragment separately. Then the duration of the time fragment should be chosen in the way in which in most cases the studied access pattern does not change significantly within one fragment. In this case, to a first approximation, one may neglect the arrival rate variations within a single fragment, and characterize each fragment by its average arrival rate. Since inter-session times are by definition above one second, the fragments also should not be too short, such that there is always a sufficient number of user access sessions for reliable statistical analysis in each fragment. Finally, it is good to have enough fragments during a single 24-hour cycle to obtain good statistics for a given day, such that possible differences in the traffic patterns on different days can be observed. In the following, we will focus on the fragment size  , which we have chosen from empirical observations.
, which we have chosen from empirical observations.
Inter-session times analysis
Figure 1(a), (b) shows the probability density functions (pdfs)  for the inter-session times obtained for separate 15-minute fragments displayed in the units of the local average times
for the inter-session times obtained for separate 15-minute fragments displayed in the units of the local average times  for six representative data sets of the local campus network and the WIDE network traces, respectively. The figure shows that the majority of pdfs are close to a simple exponential decay
for six representative data sets of the local campus network and the WIDE network traces, respectively. The figure shows that the majority of pdfs are close to a simple exponential decay  indicating that the local equilibrium assumption is relevant for most fragments, and thus the aggregated access pattern in each fragment can be characterised by a single access rate parameter
indicating that the local equilibrium assumption is relevant for most fragments, and thus the aggregated access pattern in each fragment can be characterised by a single access rate parameter  .
.

Fig. 1: (Colour online) (a), (b): local inter-session time pdfs  obtained from the local campus network (a) and from the WIDE network (b) traces, rescaled with the local average inter-session times
obtained from the local campus network (a) and from the WIDE network (b) traces, rescaled with the local average inter-session times  , with dashed lines showing simple exponentials. (c), (d): rescaled pdfs of the arrival rates
, with dashed lines showing simple exponentials. (c), (d): rescaled pdfs of the arrival rates  from six representative fragments.
from six representative fragments.
Download figure:
Standard imageFigure 1(c), (d) shows the pdfs of the access rates  from different fragments with each curve representing a single daily traffic pattern for both studied networks. The figure shows that
from different fragments with each curve representing a single daily traffic pattern for both studied networks. The figure shows that  , after being rescaled to the units of the local
, after being rescaled to the units of the local  for the given day, exhibits asymptotically Gaussian decay with moderate day-to-day variations. While none of the widely used distributions provided a high-quality fit for the entire distribution shape, similar asymptotic behaviour can be observed for the
for the given day, exhibits asymptotically Gaussian decay with moderate day-to-day variations. While none of the widely used distributions provided a high-quality fit for the entire distribution shape, similar asymptotic behaviour can be observed for the  -distribution for a large number of degrees of freedom k. Since the observational pdfs are already expressed in the units of
-distribution for a large number of degrees of freedom k. Since the observational pdfs are already expressed in the units of  , we can reduce to a single free shape parameter
, we can reduce to a single free shape parameter  , known as the coefficient of variation, where
, known as the coefficient of variation, where  is the standard deviation, providing typical values
is the standard deviation, providing typical values  and
and  for the local campus network the WIDE network, respectively.
for the local campus network the WIDE network, respectively.
In the following, for an easier comparison of networks with different access rates, without loss of generality, we simplify the notation for the normalised distributions  and
and  .
.
Superstatistical model
Accordingly, the aggregated access patterns could be approximated by a superposition of statistics for multiple fragments, each characterised by the exponential inter-session time distribution  with its own access rate β. Since β is a random variable described by its own distribution
with its own access rate β. Since β is a random variable described by its own distribution  as well, the overall inter-session time distribution for the aggregated access pattern can be described as [18]
as well, the overall inter-session time distribution for the aggregated access pattern can be described as [18]
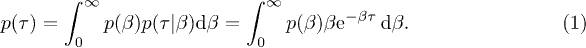
Further following [18] we note that a similar superposition of exponentials led to the overall q-exponential distribution
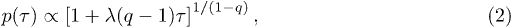
 under the assumption that
under the assumption that  is a
is a  -distribution with k degrees of freedom. Since for large k,
-distribution with k degrees of freedom. Since for large k,  -distribution decays asymptotically by Gaussian, like in the observational data, the coefficient of variation
-distribution decays asymptotically by Gaussian, like in the observational data, the coefficient of variation  leads to
leads to  and
and  , and thus we expect
, and thus we expect  and
and  for the local campus network and for the WIDE network, respectively. The q-exponential distribution has been originally suggested by Tsallis and extremises, under simple constraints, the non-additive generalisation of the Boltzmann-Gibbs entropy [19]. Additionally to previous observations in various biological, geophysical, financial and meteorological data sets [20–26], we have recently observed q-exponential distributions in the inter-packet intervals in the wide area network traffic [27].
for the local campus network and for the WIDE network, respectively. The q-exponential distribution has been originally suggested by Tsallis and extremises, under simple constraints, the non-additive generalisation of the Boltzmann-Gibbs entropy [19]. Additionally to previous observations in various biological, geophysical, financial and meteorological data sets [20–26], we have recently observed q-exponential distributions in the inter-packet intervals in the wide area network traffic [27].
To verify the validity of the above predictions, we next consider the empirical (normalised) inter-session time pdf estimates  in the aggregated traffic for the entire 24-hour periods analysed. Figures 2 and 3 show that q-exponentials make nearly perfect fits for the pdf estimates, with q values equal or slightly above the predictions given by the superstatistical model. The enhancement of q could be attributed to the broadening of the central part of the empirical distributions in the local campus network (indicated by a plateau in fig. 1(c)), and to the moderate deviations of the local
in the aggregated traffic for the entire 24-hour periods analysed. Figures 2 and 3 show that q-exponentials make nearly perfect fits for the pdf estimates, with q values equal or slightly above the predictions given by the superstatistical model. The enhancement of q could be attributed to the broadening of the central part of the empirical distributions in the local campus network (indicated by a plateau in fig. 1(c)), and to the moderate deviations of the local  distribution from simple exponential in the WIDE network (see fig. 1(b)). When the empirical distributions
distribution from simple exponential in the WIDE network (see fig. 1(b)). When the empirical distributions  for each day are inserted into eq. (1) and integrated numerically, again nearly perfect approximation for the overall
for each day are inserted into eq. (1) and integrated numerically, again nearly perfect approximation for the overall  are obtained. Finally, simulated exponential access patterns with local arrival rates β for each 15-minute fragment after their concatenation also lead to pdfs that collapse with the empirical
are obtained. Finally, simulated exponential access patterns with local arrival rates β for each 15-minute fragment after their concatenation also lead to pdfs that collapse with the empirical  , their q-exponential fits and approximations obtained by the numerical integration.
, their q-exponential fits and approximations obtained by the numerical integration.

Fig. 2: (Colour online) The circles show pdf estimates of normalised inter-session times for the local campus network downlink for six representative days. The dashed lines show the q-exponential fits, while the full line shows the numerical calculation according to eq. (1). Squares show pdfs of access patterns simulated according to the superstatistical model.
Download figure:
Standard image
Fig. 3: (Colour online) The circles show pdf estimates of normalised inter-session times for the WIDE backbone link for six representative days. Dashed lines show the q-exponential fits, while the full line shows the numerical calculation according to eq. (1). Squares show pdfs of access patterns simulated according to the superstatistical model.
Download figure:
Standard imageSession size analysis
Next we focus on the session size distributions. After appropriate normalisation, the pdfs of the session sizes nearly collapse, indicating universal shapes for each of the studied networks. Like for the inter-session times, q-exponential distribution makes a good approximation for the session sizes, with  for the local campus network and
for the local campus network and  for the WIDE network (see fig. 4). Notably, this is closely consistent with previous observations of the Zipf law in the network traffic [28].
for the WIDE network (see fig. 4). Notably, this is closely consistent with previous observations of the Zipf law in the network traffic [28].

Fig. 4: (Colour online) The circles show estimated pdfs of the normalised session sizes for the local campus network and for the WIDE backbone link for different days. The dashed lines show q-exponential fits.
Download figure:
Standard imageQueuing system simulation
To further validate the accuracy of the suggested superstatistical model, we next perform a queuing system simulation, illustrated by the sketch in fig. 5. In the simulation, we assume that sessions are served continuously and consecutively. Under this assumption, if the link is free at the session starting time ti, the sojourn time Wi from the start of the session up to its entire size vi is transmitted, simply equals the service time  , where c is the link throughput. Otherwise, if the link is occupied at time ti, the user has to wait while the request is queued in a simple first-in-first-out (FIFO) queue, and the sojourn time is given by
, where c is the link throughput. Otherwise, if the link is occupied at time ti, the user has to wait while the request is queued in a simple first-in-first-out (FIFO) queue, and the sojourn time is given by  , where
, where  is the waiting time. The key parameter characterising the queuing system performance is the average sojourn time
is the waiting time. The key parameter characterising the queuing system performance is the average sojourn time  over all user sessions.
over all user sessions.

Fig. 5: The sketch of the queuing system simulation procedure. User sessions are characterised by starting times ti and session sizes vi.  ,
,  and W are waiting, service and sojourn times, respectively.
and W are waiting, service and sojourn times, respectively.
Download figure:
Standard imageTo specify the range of c, for each daily record, we determine the total amount of the data transferred via the studied network link as the sum of all session sizes  , and find the lower bound for the link throughput
, and find the lower bound for the link throughput  , where
, where  is the record length, 24 hours in our case. If the link throughput c < c0, it is impossible to transfer the entire amount of data during time
is the record length, 24 hours in our case. If the link throughput c < c0, it is impossible to transfer the entire amount of data during time  leading to the continuous increase in the queue length and non-stationary sojourn times, indicated by the utilisation
leading to the continuous increase in the queue length and non-stationary sojourn times, indicated by the utilisation  . At
. At  , corresponding to U = 1, the system is at the edge of stationarity, performing only if the access patterns are completely regular, e.g., when both τ and v are constant (known as D/D/1 queue in Kendall's notation) [29]. Since access patterns are irregular, in practical scenarios c > c0. In our simulations, we focused on
, corresponding to U = 1, the system is at the edge of stationarity, performing only if the access patterns are completely regular, e.g., when both τ and v are constant (known as D/D/1 queue in Kendall's notation) [29]. Since access patterns are irregular, in practical scenarios c > c0. In our simulations, we focused on  that corresponds to utilisation
that corresponds to utilisation  .
.
Figures 6 and 7 show the average sojourn time estimates  as a function of the link utilisation U. The figures show that the conventional Poisson model with the same
as a function of the link utilisation U. The figures show that the conventional Poisson model with the same  and
and  but exponential pdfs (known as M/M/1 within Kendall's notation [29]) underestimates
but exponential pdfs (known as M/M/1 within Kendall's notation [29]) underestimates  by nearly two decades that is absolutely unacceptable. In contrast, the Kingman's formula that accounts for the interval and size distribution shapes via coefficients of variation
by nearly two decades that is absolutely unacceptable. In contrast, the Kingman's formula that accounts for the interval and size distribution shapes via coefficients of variation  and
and  [30]
[30]
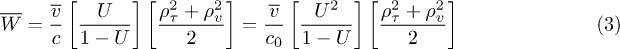
typically underestimates the empirical  only by a factor of 2 ... 4. For low utilisation 0.1 < U < 0.5 the superstatistical model is in perfect agreement with Kingman's formula. Under high utilisation
only by a factor of 2 ... 4. For low utilisation 0.1 < U < 0.5 the superstatistical model is in perfect agreement with Kingman's formula. Under high utilisation  the superstatistical model estimates are closer to the empirical results than Kingman's formula.
the superstatistical model estimates are closer to the empirical results than Kingman's formula.

Fig. 6: (Colour online) The average sojourn time estimations  as functions of the link utilisation U for empirical access patterns in the local campus network (circles), simulated access patterns with q-exponential inter-session times and session sizes (squares). For each daily record, the respective q and λ denoted in fig. 2 are used. For comparison, analytical approximations according to Kingman's formula (dashed lines) and exponential patterns with the same
as functions of the link utilisation U for empirical access patterns in the local campus network (circles), simulated access patterns with q-exponential inter-session times and session sizes (squares). For each daily record, the respective q and λ denoted in fig. 2 are used. For comparison, analytical approximations according to Kingman's formula (dashed lines) and exponential patterns with the same  and
and  (full lines) are shown additionally.
(full lines) are shown additionally.
Download figure:
Standard image
Fig. 7: (Colour online) The average sojourn time estimations  as functions of the link utilisation U for empirical access patterns in the WIDE backbone network (circles), simulated access patterns with q-exponential inter-session times and session sizes (squares). For each daily record, the respective q and λ denoted in fig. 3 are used. For comparison, analytical approximations according to Kingman's formula (dashed lines) and exponential patterns with the same
as functions of the link utilisation U for empirical access patterns in the WIDE backbone network (circles), simulated access patterns with q-exponential inter-session times and session sizes (squares). For each daily record, the respective q and λ denoted in fig. 3 are used. For comparison, analytical approximations according to Kingman's formula (dashed lines) and exponential patterns with the same  and
and  (full lines) are shown additionally.
(full lines) are shown additionally.
Download figure:
Standard imageWhile a similar analysis could not be repeated for the historic access traces, empirical evidence indicates that q-exponential approximations (with larger q, and thus with less degrees of freedom k) to a certain extent would also work in this case [16] (see also fig. 8). We believe that the similarity of the functional form is likely due to the validity of the superstatistical model also in this case, while we are unable to confirm this explicitly due to the lack of statistics.

Fig. 8: (Colour online) Pdfs of inter-session times for the historic access traces of single WWW servers at the University of Calgary  and the University of Saskatchewan
and the University of Saskatchewan  as well as session sizes for the same WWW servers (
as well as session sizes for the same WWW servers ( in both cases,
in both cases,  and
and  , respectively). The dashed lines show the respective q-exponential approximations.
, respectively). The dashed lines show the respective q-exponential approximations.
Download figure:
Standard imageFigure 9 shows the relation between the model parameters q and λ for both inter-session times and session sizes. The figure shows that for inter-session times there is an approximately linear relation between q and λ, while for session sizes the data scatter, and no universal relation can be observed. We think that inter-session time distributions depend rather on the collective user activity, while session size distributions also depend on the particular data content transferred in each network.

Fig. 9: (Colour online) Dependence between the model parameters q and λ for (a) inter-session times and (b) session sizes. The full line in (a) shows a linear regression fit, while the dashed lines indicate its 95% confidence interval.
Download figure:
Standard imageConclusion
To summarise, we have suggested a universal statistical description for the collective access patterns in the internet traffic dynamics both at local and wide area network levels that takes into account erratic fluctuations imposed by cooperative user behaviour. Our description is based on the superstatistical approach and leads to the q-exponential inter-session time and session size distributions that are also in a nearly perfect agreement with empirical observations. The validity of the proposed description is confirmed explicitly by the analysis of complete 10-day traffic traces from the WIDE backbone link and from the local campus area network downlink as well as the historic access patterns from single WWW servers. The suggested approach effectively accounts for the complex interplay of both "calm" and "bursty" user access patterns within a single-model setting. Remarkably, access patterns to single servers are characterised by larger q values, indicating that they are more vulnerable to erratic traffic bursts in their access patterns. This can be easily interpreted in terms of information spreading models. Once any piece of information hosted on these particular servers attracts attention, the access rate to this particular server increases drastically. In the local and tightly linked network many users have common interests, and share information with each other intensively, leading to the pronounced bursty patterns at the local network downlink. In contrast, in large networks local bursts caused by a limited number of users are largely averaged out, leading to nearly Poisson traffic flow.
Remarkably, very similar properties have been observed very recently in the rainfall dynamics, with a q-exponential with q close to one for the pdf of the intervals between rainfall events, and a q-exponential with q close to 1.3–1.5 for the pdf of rainfall event sizes [26]. Altogether with observations of similar functional forms in the inter-occurrence intervals between earthquakes [24], large returns in financial markets [21,23], similar nucleotides in DNA [22] and many other complex systems [25], this might be an indicator of a deeper universality in the dynamical behaviour and structural organisation of very different complex systems leading to their successive description by the superstatistical model approach.
Limitations of our study include its restriction to academic community networks. While we expect that similar results could be to a certain extent reproduced for other communities like corporate or general public networks, the model parameters q and λ may vary significantly, especially for the session size distributions, since they largely depend on the characteristic data content for the given network. Furthermore, while the suggested model accounts for the variability of the local access rates, it still treats the consecutive inter-session intervals and session sizes as independent. While this assumption leads to reasonable quality asymptotic fits, in most practical scenarios it is likely violated. Once a certain piece of information attracts attention, intervals τ are significantly shorter than the average interval  , leading to the inherent conditional memory in the sequence of intervals τ, and since a large number of sessions are due to the access to the same piece of information, respective session sizes v would be also correlated. Neglecting these effects may disrupt the reproducibility of long-term memory effects such as return intervals between large events in the aggregated traffic [15] this way limiting their predictability [31]. As an outlook, we suggest that our model could be further extended by taking into account the correlations in the sequence of local intensities β, this way accounting to a certain extent for the long-term memory effects. Despite these obvious limitations, the suggested model nevertheless provides with reasonable accuracy estimates of the average sojourn time
, leading to the inherent conditional memory in the sequence of intervals τ, and since a large number of sessions are due to the access to the same piece of information, respective session sizes v would be also correlated. Neglecting these effects may disrupt the reproducibility of long-term memory effects such as return intervals between large events in the aggregated traffic [15] this way limiting their predictability [31]. As an outlook, we suggest that our model could be further extended by taking into account the correlations in the sequence of local intensities β, this way accounting to a certain extent for the long-term memory effects. Despite these obvious limitations, the suggested model nevertheless provides with reasonable accuracy estimates of the average sojourn time  , as indicated by the queuing system simulation, this way largely overcoming the failure of Poisson modelling of the Internet traffic dynamics.
, as indicated by the queuing system simulation, this way largely overcoming the failure of Poisson modelling of the Internet traffic dynamics.
Acknowledgments
We would like to acknowledge the financial support of this work by the Ministry of Education and Science of the Russian Federation (8.324.2014/K) and by the Russian Foundation for Basic Research (16-37-00374). We also like to thank Oleg Yu. Khudyakov for providing the local network traffic data as well as two anonymous referees for their helpful comments.