


Abstract
We ask how quantum theory compares to more general physical theories from the point of view of dimension. To do so, we first give two model-independent definitions of the dimension of physical systems, based on measurements and the capacity of storing information. While both definitions are equivalent in classical and quantum mechanics, they are different in generalized probabilistic theories. We discuss in detail the case of a theory known as 'boxworld', and show that such a theory features systems with dimension mismatch. This dimension mismatch can be made arbitrarily large using an amplification procedure. Furthermore, we show that the dimension mismatch of boxworld has strong consequences on its power for performing information-theoretic tasks, leading to the collapse of communication complexity and to the violation of information causality. Finally, we discuss the consequences of a dimension mismatch from the perspective of thermodynamics, and ask whether this effect could break Landauerʼs erasure principle and thus the second law.
Export citation and abstract BibTeX RIS

Content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Any theory aimed at explaining and predicting experimental observations makes use of a concept of dimension, which represents the number of degrees of freedom considered in the model. Loosely speaking, the dimension of a system corresponds to the number of perfectly distinguishable configurations the system can be prepared in. For quantum systems, this corresponds to the Hilbert space dimension.
The dimension of a physical system (classical or quantum) also characterizes the amount of classical information that can be encoded in the system and subsequently retrieved. Notably, classical and quantum systems of the same dimension d can carry the same amount of classical information, namely 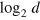 bits of information [1]. However, it is not the case that a classical system of dimension d can always be substituted for a quantum system of the same dimension d. In fact, reproducing the behaviour of the simplest quantum system, the qubit, requires classical systems of infinite dimensions [2, 3]. This shows that quantum theory is much more economical in terms of dimension compared to classical physics [4]. This is because classical and quantum systems are fundamentally different objects. On the one hand, for a classical system, the dimension d always corresponds to the number of pure states the system can be prepared in. For finite dimension d, there are d pure states. On the other hand, a quantum system, say a qubit, can be prepared in infinitely many different pure states, and two real numbers (hence infinitely many classical bits) are necessary to characterize a pure state. Indeed this difference has a strong impact on the capabilities of each theory for information processing.
bits of information [1]. However, it is not the case that a classical system of dimension d can always be substituted for a quantum system of the same dimension d. In fact, reproducing the behaviour of the simplest quantum system, the qubit, requires classical systems of infinite dimensions [2, 3]. This shows that quantum theory is much more economical in terms of dimension compared to classical physics [4]. This is because classical and quantum systems are fundamentally different objects. On the one hand, for a classical system, the dimension d always corresponds to the number of pure states the system can be prepared in. For finite dimension d, there are d pure states. On the other hand, a quantum system, say a qubit, can be prepared in infinitely many different pure states, and two real numbers (hence infinitely many classical bits) are necessary to characterize a pure state. Indeed this difference has a strong impact on the capabilities of each theory for information processing.
The above shows that comparing classical and quantum physics from the point of view of dimension gives an interesting perspective on quantum mechanics, first as a physical theory but also on its power for information processing. More generally, one may ask how quantum mechanics compares to other physical theories, such as generalized probabilistic theories (GPTs) [5], a general class of theories featuring quantum and classical mechanics as special cases. In fact, understanding what features identify quantum mechanics among GPTs is a deep question, which may lead to a reformulation of quantum theory based on more physical axioms, see [5–11]. Discussing information processing and physical properties of GPTs may give insight to this question [5, 12–17].
However, comparing different physical theories from the point of view of dimension is in general not a trivial issue. This is due to the fact that each theory has its own notion of dimension, usually based on the structure of the theory itself—e.g., in quantum mechanics, dimension is associated with the Hilbert space, the basic structure supporting quantum states and measurements. But one may ask if there exists a universal, model-independent definition of dimension that could be used to compare different models.
Here, we explore this problem, with the goal of finding out what is special about quantum mechanics as far as dimension is concerned. We start by discussing two definitions of dimension which we believe are natural. First we consider a notion of dimension related to the measurements that can be performed on a system. Our second notion of dimension refers to the amount of information that is potentially extractable from the system. While these two notions of dimension happen to coincide in classical and quantum physics, they are nevertheless different in general. We show that this is the case in a specific GPT known as 'boxworld' [5]. We say that such a model features a dimension mismatch.
Moreover, the dimension mismatch of boxworld appears to be directly related to its astonishing information-theoretic power. So far the latter has been discussed in the context of spatially separated systems, that is considering communication tasks assisted by non-local (but no-signaling) correlations, see [19–33]. In particular, it was shown that the existence of maximally non-local correlations (Popescu–Rohrlich (PR) boxes [18]) would lead to the collapse communication complexity [19], and to the violation of the principle of information causality [25]. Here we recover these results but following a different approach. Considering only single systems, we show that both the collapse of communication complexity and the violation of information causality are direct consequences of the dimension mismatch of boxworld.
Finally we discuss the consequences of a dimension mismatch from a more physical perspective, related to thermodynamics. Specifically, we explore these ideas in the context of Maxwellʼs demon and Landauerʼs erasure principle [36–38], and raise the question of whether theories with a dimension mismatch would break the second law of thermodynamics. Recent works [39–41] have also discussed thermodynamics in GPTs, however following a different approach.
2. Two definitions of dimension
We start by giving two model-independent definitions of dimension. While other definitions can indeed be considered, we believe the present ones are natural choices.
Measurement dimension, which we denote here as dm, is defined as the number of orthogonal pure states of the system, i.e., that can be perfectly distinguished in a single measurement5
. Hence there is a set of states 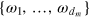 and a measurement with dm outcomes, such that outcome i has probability one for state
and a measurement with dm outcomes, such that outcome i has probability one for state 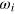 . This implies that
. This implies that 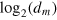 bits of information can be encoded in the system and subsequently retrieved via a measurement. This is definition of dimension represents arguably the most natural choice, and has been used previously, e.g., in [6].
bits of information can be encoded in the system and subsequently retrieved via a measurement. This is definition of dimension represents arguably the most natural choice, and has been used previously, e.g., in [6].
The second definition, information dimension, which we denote as di, is the number of states of the system that are perfectly distinguishable pairwise. More formally, di is the largest integer such that there exists a set of states 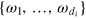 such that for any pair
such that for any pair 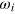 ,
, 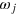 with
with 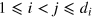 , there is a measurement that perfectly distinguishes
, there is a measurement that perfectly distinguishes 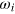 from
from 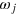 . Note that these measurements can be different for all pairs of states, and can be chosen to be binary without loss of generality. In other words, information dimension characterizes the maximal number of states which are pairwise orthogonal.
. Note that these measurements can be different for all pairs of states, and can be chosen to be binary without loss of generality. In other words, information dimension characterizes the maximal number of states which are pairwise orthogonal.
Finally, note that the measurement dimension is always smaller than or equal to the information dimension. Indeed, if a system can be prepared in dm different states that can be perfectly distinguished in a single measurement, then each pair of states in this set is also perfectly distinguishable by this measurement, hence 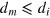 . Below, we shall see that in quantum mechanics equality holds, i.e., dm = di, while there exist more general theories where this is not the case; that is, where
. Below, we shall see that in quantum mechanics equality holds, i.e., dm = di, while there exist more general theories where this is not the case; that is, where 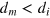 .
.
3. Measurement and information dimensions coincide in classical and quantum mechanics
We start with the case of quantum theory. Consider a quantum system, the states of which are given by vectors in a Hilbert space of dimension d, i.e., 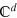 . Then, any orthonormal basis consists of d pure states. One can always define an observable acting on
. Then, any orthonormal basis consists of d pure states. One can always define an observable acting on 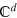 , formed by the d states of an orthonormal basis. Thus, we get that
, formed by the d states of an orthonormal basis. Thus, we get that 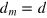 , which is the measurement dimension equal to the Hilbert space dimension.
, which is the measurement dimension equal to the Hilbert space dimension.
It is also straightforward to see that the information dimension is equal to the Hilbert space dimension. Consider a set of d quantum states which are perfectly distinguishable pairwise. These states are pairwise orthogonal and thus form an orthonormal basis in 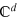 , hence we get that
, hence we get that 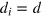 .
.
We conclude that for quantum systems, the measurement dimension and information dimension coincide. Indeed, this is also the case for classical systems. A classical system of dimension d features d pure states, which are all pairwise distinguishable. On the other hand, a collection of classical states which are all pairwise distinguishable can all be distinguished by a single measurement.
4. Dimension mismatch in GPTs
While it may come as no surprise that the measurement dimension and information dimension coincide in quantum mechanics, we shall see that this is not necessarily the case in GPTs. When the measurement dimension and information dimension differ, i.e., when 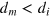 , we say that the theory features a dimension mismatch. Before discussing this aspect, we give a brief review of the concepts of GPTs; more comprehensive reviews are available in the literature [5, 12, 16, 42].
, we say that the theory features a dimension mismatch. Before discussing this aspect, we give a brief review of the concepts of GPTs; more comprehensive reviews are available in the literature [5, 12, 16, 42].
4.1. Basic concepts
The state of a system is an abstract object that defines the outcome probabilities for all the measurements that can be performed on a system. The state space Ω is the set of states that a system can be prepared in. The natural requirements that the model is no-signaling (i.e., it does not allow for instantaneous transmission of information) and that probabilistic mixtures of states are also valid states enforce convexity and linearity of Ω. Ω (assumed here to be closed) thus lives in a vector space. A state corresponds to a vector 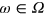 . Pure states are extremal points of Ω. All other states are called mixed states, as they can be decomposed as a convex mixture of pure states.
. Pure states are extremal points of Ω. All other states are called mixed states, as they can be decomposed as a convex mixture of pure states.
Consider now measurement outcomes, usually termed effects. These are affine maps 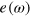 from Ω to the interval
from Ω to the interval ![$[0,1]$](https://content.cld.iop.org/journals/1367-2630/16/12/123050/revision1/njp505622ieqn21.gif) , hence assigning a probability to each state ω. A measurement is then given by a set of effects
, hence assigning a probability to each state ω. A measurement is then given by a set of effects 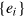 such that
such that 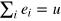 , where u is called the unit effect, i.e., the effect assigning value one to every state in Ω. This condition ensures that all states are normalized. Similarly to quantum theory, a measurement is given by a decomposition of the unit effect (the identity), ensuring that the probabilities for each outcome sum to one. The set of valid effects is given by
, where u is called the unit effect, i.e., the effect assigning value one to every state in Ω. This condition ensures that all states are normalized. Similarly to quantum theory, a measurement is given by a decomposition of the unit effect (the identity), ensuring that the probabilities for each outcome sum to one. The set of valid effects is given by 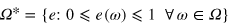 , which is the convex hull of extremal effects, the unit effect, and the zero effect.
, which is the convex hull of extremal effects, the unit effect, and the zero effect.
Let us now discuss our above notions of dimension in the context of GPTs. We focus here on a specific GPT known as boxworld [5], studied later in e.g., [43–45]. An interesting aspect of this model is that it features non-local correlations (i.e., leading to violation of Bell inequalities); in fact, boxworld features all possible no-signaling correlations, such as the PR box. We start by discussing the simplest system in boxworld. This is a single physical system on which two possible binary measurements can be performed. Such a system is usually represented as a 'black box' with two possible inputs (or pure measurements), denoted x = 0, 1, and two possible outputs (or measurement outcomes), denoted a = 0, 1 (see figure 1(a)). The pure states of this system are those for which the outcome a is a deterministic function of the input x, that is

where 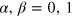 and ⨁ denotes addition modulo 2. There are thus four pure states. Using the vectorial representation of GPTs, the state space Ω of this simple system can be conveniently represented by a 2D cube, i.e., a square (see figure 1(b)). The vertices of the square represents the four pure states ωj with j = 1, ..., 4. All other states are convex mixtures of the pure states, and are thus mixed states. The set of effects
and ⨁ denotes addition modulo 2. There are thus four pure states. Using the vectorial representation of GPTs, the state space Ω of this simple system can be conveniently represented by a 2D cube, i.e., a square (see figure 1(b)). The vertices of the square represents the four pure states ωj with j = 1, ..., 4. All other states are convex mixtures of the pure states, and are thus mixed states. The set of effects 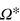 , given by the dual of the state space, is also a 2D cube, but rotated compared to the state space (see figure 1(c)). Pure (or extremal) effects correspond to the four possible measurement outcomes, i.e., inputting x in the box and getting outcome a. For more details on this system, in particular on its state space, we refer the reader to [5, 12] .
, given by the dual of the state space, is also a 2D cube, but rotated compared to the state space (see figure 1(c)). Pure (or extremal) effects correspond to the four possible measurement outcomes, i.e., inputting x in the box and getting outcome a. For more details on this system, in particular on its state space, we refer the reader to [5, 12] .

Figure 1. The simplest system in boxworld: the g-bit. (a) This system can be understood as a black box taking a binary input x = 0, 1 and returning a binary output a = 0, 1. The state of the system is described by a conditional probability distribution 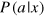 . (b) The state space Ω of the system can be represented as a square in
. (b) The state space Ω of the system can be represented as a square in 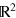 . The system thus features four pure states,
. The system thus features four pure states, 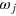 . For each pure state, the outcome a is a deterministic function of the input x, as indicated. At the centre of Ω is the maximally mixed state, that is, where a is independent of x and random. (c) The space of effects,
. For each pure state, the outcome a is a deterministic function of the input x, as indicated. At the centre of Ω is the maximally mixed state, that is, where a is independent of x and random. (c) The space of effects, 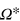 , is the dual of Ω. It features four extremal effects, ej, which correspond to the four measurement outcomes, i.e., obtaining output a for a given input x. The probability of ej on any state is easily determined. For instance, effect e1 has probability one for states
, is the dual of Ω. It features four extremal effects, ej, which correspond to the four measurement outcomes, i.e., obtaining output a for a given input x. The probability of ej on any state is easily determined. For instance, effect e1 has probability one for states 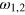 and probability zero for states
and probability zero for states 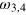 . There are two pure measurements for this system: the first is composed of extremal effects e1 and e3, hence corresponding to input x = 0; the second is composed of extremal effects e2 and e4, hence corresponding to input x = 1. Note that
. There are two pure measurements for this system: the first is composed of extremal effects e1 and e3, hence corresponding to input x = 0; the second is composed of extremal effects e2 and e4, hence corresponding to input x = 1. Note that 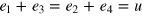 , where u is the unit effect.
, where u is the unit effect.
Download figure:
Standard image High-resolution image
Figure 2. Cost of erasing a g-bit. We present a simple cycle for erasing the information contained in a g-bit. (a) Consider a g-bit in some fixed initial state 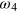 (as indicated by the red dot). (b) After an arbitrary transformation, some (unknown) information may have been encoded in the g-bit, the g-bit is an arbitrary and unknown state. (c) In order to erase the information contained in the g-bit, one starts by performing a measurement, here x = 0, giving an outcome, say a = 0. According to the measurement dynamics described in the main text, i.e., the procedure we adopted for defining the post-measurement state, the g-bit is now in the pure state
(as indicated by the red dot). (b) After an arbitrary transformation, some (unknown) information may have been encoded in the g-bit, the g-bit is an arbitrary and unknown state. (c) In order to erase the information contained in the g-bit, one starts by performing a measurement, here x = 0, giving an outcome, say a = 0. According to the measurement dynamics described in the main text, i.e., the procedure we adopted for defining the post-measurement state, the g-bit is now in the pure state 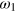 . (d) To bring the system in the initial state, one must erase the (classical) information about the measurement outcome a, now stored in a classical register. Having access to a thermal bath at temperature T, the energy cost of this operation is
. (d) To bring the system in the initial state, one must erase the (classical) information about the measurement outcome a, now stored in a classical register. Having access to a thermal bath at temperature T, the energy cost of this operation is 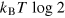 . Finally, the state of the g-bit must be reset to the pure state
. Finally, the state of the g-bit must be reset to the pure state 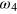 . Since all pure states have here the same energy, this operation can be done for free. Hence the cycle is complete. Finally, notice that the above protocol can be straightforwardly generalized to erase a hypercube-bit. The energy cost of such a procedure is
. Since all pure states have here the same energy, this operation can be done for free. Hence the cycle is complete. Finally, notice that the above protocol can be straightforwardly generalized to erase a hypercube-bit. The energy cost of such a procedure is 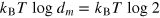 .
.
Download figure:
Standard image High-resolution imageClearly, our system features only two ideal measurements, which correspond to input x = 0 or x = 1 in the box. Both measurements have two outcomes, hence we have that the measurement dimension is dm = 2. This system can be used to transmit exactly one bit of information, and thus can be considered as a generalization of the qubit—in fact, it is often referred to as a g-bit, i.e., generalized bit [5]. Moreover, such a system can be considered as the reduced local part of a PR box.
On the other hand, we see immediately that the information dimension is di = 4, since any pair of pure states can be perfectly distinguished by performing either the x = 0 or x = 1 measurement. Hence we see that our g-bit system features a dimension mismatch, as 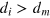 .
.
4.2. Amplification of dimension mismatch
While the g-bit has a dimension mismatch of a factor of 2, we will see now that there exist in boxworld systems with an arbitrarily large dimension mismatch. Such systems, which are a straightforward generalization of the g-bit, can in fact be constructed by composing g-bits. Hence, dimension mismatch can be amplified.
We presented the g-bit system as a black box featuring two possible (pure) binary measurements x = 0, 1, with outcome a = 0, 1. Consider now a black box with D possible binary measurements 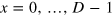 , with outcome a = 0, 1. Following the g-bit construction, the state space of our system is now a hypercube in
, with outcome a = 0, 1. Following the g-bit construction, the state space of our system is now a hypercube in 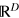 . The system features
. The system features 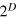 pure states. Each state associates a deterministic outcome (a = 0 or a = 1) to each of the D possible measurements. In the state space, each pure state corresponds to one of the vertices of the D-dimensional hypercube, and can therefore be conveniently described by a vector of the form
pure states. Each state associates a deterministic outcome (a = 0 or a = 1) to each of the D possible measurements. In the state space, each pure state corresponds to one of the vertices of the D-dimensional hypercube, and can therefore be conveniently described by a vector of the form 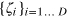 , where
, where 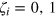 denotes the outcome obtained when performing measurement
denotes the outcome obtained when performing measurement 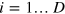 .
.
The measurement dimension is dm = 2 for all D, since all pure measurements are binary. Hence, the system can be viewed as a generalization of a bit, since only one bit of information can be retrieved by performing a measurement on it. From now on, we will thus refer to this system as a hypercube bit 6 .
On the other hand, any pair of pure states of the hypercube bit can be perfectly distinguished, since there is (at least) one measurement x for which two different pure states give different outcomes. Therefore, the information dimension is 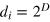 . Hence, as D increases, we obtain an arbitrarily large dimension mismatch.
. Hence, as D increases, we obtain an arbitrarily large dimension mismatch.
Finally, we present a procedure to construct hypercube bits by composing g-bits. To define the composition of systems in a GPT, one has to choose a tensor product. In boxworld, one uses the 'maximal tensor product' [5, 12]. Intuitively, this means the following: a bipartite (or more generally multipartite) system is considered as a valid state, if (i) it does not allow for instantaneous transmission of information (i.e., it is no-signaling) and (ii) upon performing a measurement on one system, and for each outcome of this measurement, the other system is prepared (or steered) into a state that is valid (i.e., inside the initial state space)7 .
Consider the composition of two g-bits. The resulting system can be represented as a black box shared between two observers, such that each observer can perform one out of two possible measurements with binary outcomes. We denote xi the measurement of observer i and ai its outcome. The state space obtained by taking the maximal tensor product of two g-bits has been extensively discussed [46]. For our purpose, it is convenient to express the pure states of this bipartite state space according to their correlations:

where 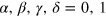 . We thus obtain 16 pure states8
, which can be divided into two classes: (i) 8 local deterministic states, for which
. We thus obtain 16 pure states8
, which can be divided into two classes: (i) 8 local deterministic states, for which 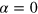 , and (ii) 8 non-local PR boxes, for which
, and (ii) 8 non-local PR boxes, for which 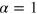 . Note that states in class (i) can be obtained by taking two copies of a g-bit: hence
. Note that states in class (i) can be obtained by taking two copies of a g-bit: hence 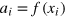 . On the contrary, states in class (ii) feature non-local correlations (e.g., of the form
. On the contrary, states in class (ii) feature non-local correlations (e.g., of the form 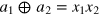 ), which achieve maximal violation of the Clauser–Horne–Shimony–Holt Bell inequality. To ensure no-signaling, such states have full local randomness, that is
), which achieve maximal violation of the Clauser–Horne–Shimony–Holt Bell inequality. To ensure no-signaling, such states have full local randomness, that is 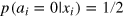 .
.
At this point, our composed system has dm = 4. To obtain a hypercube bit, we project it onto a subspace. More precisely, we apply the projection 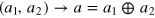 . This is analogous to parity projections in quantum theory. The resulting system has measurement dimension dm = 2 and information dimension di = 16, and is in fact isomorphic to a hypercube bit with D = 4.
. This is analogous to parity projections in quantum theory. The resulting system has measurement dimension dm = 2 and information dimension di = 16, and is in fact isomorphic to a hypercube bit with D = 4.
The above procedure can be applied starting from the composition of k g-bits, hence resulting in a system that is isomorphic to a hypercube of dimension 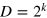 . Specifically, one considers all pure states in the maximal tensor product of k g-bits with correlations of the form
. Specifically, one considers all pure states in the maximal tensor product of k g-bits with correlations of the form 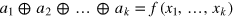 where f is an arbitrary deterministic Boolean function of k bits—note that in general there exist additional pure states which are not of this form [47]. Hence we obtain
where f is an arbitrary deterministic Boolean function of k bits—note that in general there exist additional pure states which are not of this form [47]. Hence we obtain 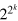 pure states. After performing the projection
pure states. After performing the projection 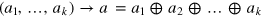 we get a state space that is isomorphic to the hypercube of dimension
we get a state space that is isomorphic to the hypercube of dimension 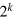 . Therefore, when composing g-bits using the maximal tensor product (in other words assuming only no-signaling), we obtain systems with an arbitrarily large dimension mismatch.
. Therefore, when composing g-bits using the maximal tensor product (in other words assuming only no-signaling), we obtain systems with an arbitrarily large dimension mismatch.
Finally, note that the possibility of amplifying dimension mismatch depends on the way systems are composed, i.e., which tensor product is chosen. Since the choice of tensor product will affect the strength of non-local correlations featured in the model, there appears to be a direct relation between the possibility of amplifying dimension mismatch and the strength of non-local correlations. This aspect will be discussed in more detail in section 6.
5. Dimension mismatch and communication power
In this section, we investigate the consequences for information processing of the dimension mismatch of hypercube bits. We consider information-theoretic tasks in GPTs using protocols with 'one-way communication,' e.g., where Alice sends a system to Bob [5]. Specifically, we consider the situation in which Alice can prepare a hypercube bit in any desired state, encoding certain information in it. Then she sends the system to Bob, via an adequate (non-classical) channel. Bob performs a measurement on the received hypercube bit, which allows him to extract part of the information that Alice encoded in the system.
We shall see that the dimension mismatch of hypercube bits enhances their communication power compared to classical and quantum resources, leading to maximal violation of information causality and to the collapse of communication complexity. In fact, these enhancements in communication power are captured by the fact that hypercube bits are tailored for computing the index function, which we discuss first.
5.1. Index function
Consider the following communication complexity problem. Alice receives a uniformly sampled bit string of length n, 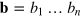 . Bob receives a random index
. Bob receives a random index 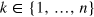 . The goal for Bob is to output the value of the bit bk. This problem is known as computing the index function. Its classical and quantum communication complexity is n bits [48]. Hence, using classical or quantum systems for the index function requires systems of dimension increasing exponentially with n. Below we give a protocol which uses one hypercube bit of dimension D = n and computes the index function on inputs of length n. Since we have here that dm = 2 independently of n, this is in stark contrast with classical and quantum resources. Note that a similar protocol was presented in [5], however using N gbits (with
. The goal for Bob is to output the value of the bit bk. This problem is known as computing the index function. Its classical and quantum communication complexity is n bits [48]. Hence, using classical or quantum systems for the index function requires systems of dimension increasing exponentially with n. Below we give a protocol which uses one hypercube bit of dimension D = n and computes the index function on inputs of length n. Since we have here that dm = 2 independently of n, this is in stark contrast with classical and quantum resources. Note that a similar protocol was presented in [5], however using N gbits (with 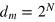 ) instead of a single hypercube bit.
) instead of a single hypercube bit.
After receiving her input bit string 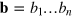 , Alice prepares a hypercube system of dimension D = n in a pure state
, Alice prepares a hypercube system of dimension D = n in a pure state 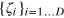 such that
such that 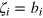 . Hence the outcome of measurement xi is
. Hence the outcome of measurement xi is 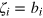 (for i = 1,..., D). Then she sends the system to Bob. Upon receiving index k, Bob performs measurement xk and obtains outcome
(for i = 1,..., D). Then she sends the system to Bob. Upon receiving index k, Bob performs measurement xk and obtains outcome 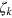 . He thus retrieves correctly the bit value bk.
. He thus retrieves correctly the bit value bk.
Note that the ability to compute the index function depends only on the information dimension di, but is independent of the measurement dimension dm. For hypercube bits, the index function can be computed for arbitrary n (taking D = n). Nevertheless, the measurement dimension remains fixed, dm = 2, meaning that the system is binary, in the sense that only one bit of information can be retrieved by performing a measurement on it. This is thus in stark contrast with systems featuring no dimension mismatch, such as classical and quantum systems.
5.2. Information causality
The principle of information causality [25] was initially formulated in a scenario where classical communication is assisted with pre-shared non-local correlations. The principle limits the strength of non-local correlations by restricting the power of classical communication assisted by non-local correlations. In certain cases, information causality allows one to recover the boundary between quantum and super-quantum correlations [25, 26].
Here we consider a variant of information causality, in a scenario with one-way communication. Alice encodes information in a physical system (for instance, a hypercube bit) and sends it to Bob, who retrieves information by performing a measurement on the system. In this context, the principle should limit Bobʼs conditional gain of information depending on the information capacity of the physical system that is sent. Consider Alice receiving a bit string of length n, 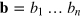 , and Bob receiving an index
, and Bob receiving an index 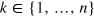 and asked to give a guess β for the value of bit bk. Then information causality can be written as
and asked to give a guess β for the value of bit bk. Then information causality can be written as

where dm is the measurement dimension of the system and 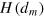 is its capacity; that is, the number of bits of information that are retrieved from the system by performing a measurement on it9
.
is its capacity; that is, the number of bits of information that are retrieved from the system by performing a measurement on it9
.
Indeed, this task is essentially identical to the index problem discussed above. Hence by using a hypercube bit of dimension D = n, Alice and Bob can achieve 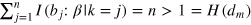 and violate maximally information causality. In other words, one can implement a perfect 1-out-of-n random access code [48] using a hypercube bit of dimension D = n.
and violate maximally information causality. In other words, one can implement a perfect 1-out-of-n random access code [48] using a hypercube bit of dimension D = n.
Note that a related formulation of information causality for single systems was recently considered in an axiomatic reformulation of quantum theory [10].
5.3. Collapse of communication complexity
The collapse of communication complexity is arguably the strongest demonstration of the communication power of PR boxes [20, 22]. Initially proved for pure PR boxes [19], the result was later extended to classes of noisy PR boxes [21, 24]. While these works considered classical communication assisted with pre-shared non-local resources, we consider here the case where Alice prepares a physical system and sends it to Bob.
Consider a Boolean function 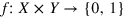 , where X denotes the set of possible bit strings
, where X denotes the set of possible bit strings 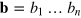 received by Alice, and Y the set of bit strings
received by Alice, and Y the set of bit strings  for Bob. The goal is that Bob should output the value of the function
for Bob. The goal is that Bob should output the value of the function 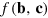 for all possible inputs. The communication complexity of the function is then the amount of information that needs to be communicated from Alice to Bob in order for Bob to compute the function. Classically, this represents the number of bits C required by the most economical protocol, hence this protocol uses classical systems of dimension
for all possible inputs. The communication complexity of the function is then the amount of information that needs to be communicated from Alice to Bob in order for Bob to compute the function. Classically, this represents the number of bits C required by the most economical protocol, hence this protocol uses classical systems of dimension 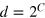 . Using quantum resources, the communication complexity is the number of qubits Q necessary to compute the function, hence the optimal protocol requires quantum systems of Hilbert space dimension
. Using quantum resources, the communication complexity is the number of qubits Q necessary to compute the function, hence the optimal protocol requires quantum systems of Hilbert space dimension 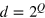 . More generally, we see that a protocol using a system of measurement dimension dm has communication complexity
. More generally, we see that a protocol using a system of measurement dimension dm has communication complexity 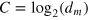 , as this represents the amount of information that is extracted from the system by Bobʼs measurement.
, as this represents the amount of information that is extracted from the system by Bobʼs measurement.
By adapting the index protocol discussed above, any Boolean function can be computed by having Alice sending a single hypercube bit to Bob. The protocol is as follows. Suppose Alice and Bob want to compute a given function f. Upon receiving her input bit string 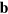 , Alice computes locally the value of the function
, Alice computes locally the value of the function 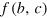 for all possible input bit strings
for all possible input bit strings 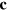 of Bob. Next, she prepares a hypercube bit of dimension
of Bob. Next, she prepares a hypercube bit of dimension 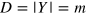 (i.e., the number of possible inputs y for Bob) in the state
(i.e., the number of possible inputs y for Bob) in the state 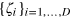 such that
such that 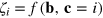 . Hence, we need a hypercube bit of sufficiently large dimension, such that D = 2m. Bob, upon receiving his bit string
. Hence, we need a hypercube bit of sufficiently large dimension, such that D = 2m. Bob, upon receiving his bit string 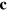 , performs the corresponding measurement and accesses the bit
, performs the corresponding measurement and accesses the bit 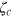 , hence the value of the function
, hence the value of the function 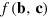 .
.
Since the above protocol uses a single hypercube bit, it has trivial communication complexity C = 1, independently of the size of the input bit strings. Indeed, this is in stark contrast with the case of classical or quantum resources, for which there exist functions whose communication complexity is not trivial, that is, C is an increasing and unbounded function of the size of the problem [49].
5.4. Steering
We just showed that the existence of hypercube bits would lead to the violation of information causality and to the collapse communication complexity. Hence, we recover previously known results about the dramatic enhancement of communication power observed in boxworld compared to quantum theory [19, 25]. However, we followed a different approach, similar to considerations made in [5]. While previous works [19, 25] considered the power of classical communication assisted by the strong non-local correlations (i.e., PR boxes) available in boxworld, we studied here the power of hypercube bits for information-theoretic tasks, considering protocols in which Alice prepares a hypercube bit and then sends it to Bob, who finally performs a measurement on it. It turns out, however, that both approaches can be connected, as the communication of a hypercube bit is essentially equivalent to the communication of one classical bit assisted with PR boxes, as we shall see below.
To see this, consider first the case in which Alice prepares a hypercube bit of dimension D in a state 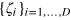 and sends it to Bob who recovers bit bk by performing measurement k. This protocol can be simulated by D PR boxes, shared between Alice and Bob, and one bit of classical communication from Alice to Bob. We denote the inputs (outputs) of PR box number i by xi (ai) for Alice and yi (bi) for Bob. First, Alice enters bit
and sends it to Bob who recovers bit bk by performing measurement k. This protocol can be simulated by D PR boxes, shared between Alice and Bob, and one bit of classical communication from Alice to Bob. We denote the inputs (outputs) of PR box number i by xi (ai) for Alice and yi (bi) for Bob. First, Alice enters bit 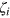 in PR box number i for
in PR box number i for 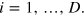 She then sends to Bob the bit
She then sends to Bob the bit 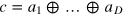 . Bob, who wants to retrieve bit k, inputs yk = 1 and yj = 0 for
. Bob, who wants to retrieve bit k, inputs yk = 1 and yj = 0 for 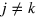 . Finally, Bob outputs
. Finally, Bob outputs 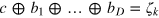 .
.
Consider now the converse problem. We want to simulate a situation where Alice and Bob share n PR boxes: Alice sends one bit of classical communication to Bob who then extracts one bit of information 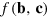 , which depends on the inputs
, which depends on the inputs 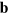 and
and 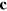 they received. It is sufficient here to consider a deterministic function f. Upon receiving her input b, Alice computes locally
they received. It is sufficient here to consider a deterministic function f. Upon receiving her input b, Alice computes locally 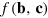 for all possible inputs of Bob c = 1,...,m. She then prepares a hypercube bit of dimension D = m in a state
for all possible inputs of Bob c = 1,...,m. She then prepares a hypercube bit of dimension D = m in a state  , such that
, such that 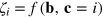 . Upon receiving the hypercube bit from Alice, Bob performs measurements to retrieve the bit
. Upon receiving the hypercube bit from Alice, Bob performs measurements to retrieve the bit 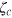 , and retrieves the desired bit
, and retrieves the desired bit 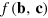 , as he would have in the situation they wanted to simulate.
, as he would have in the situation they wanted to simulate.
Thus, we conclude that the communication of a hypercube bit can be replaced by a single bit of classical communication assisted by a sufficient number of PR boxes, and vice versa. The fact that the hypercube bit has measurement dimension dm = 2 corresponds to the fact that a single bit of classical communication is sufficient in the above protocol. Also, the information dimension di is related to the number of required PR boxes in the protocol we gave above.
6. Discussion
We have discussed the problem of characterizing the dimension of physical systems in a model independent way. We introduced two definitions for the dimension which we believe are rather natural. One is related to the number of outcomes of a pure measurement and the other to the number of pairwise perfectly distinguishable states. These two notions of dimension coincide in quantum mechanics and are equal to the Hilbert space dimension, the usual (but model-dependent) measure of dimensionality of quantum systems. We showed that this is not the case in certain generalized models, such as boxworld. Hence these models feature a dimension mismatch, in the sense that the number of states which are pairwise perfectly distinguishable exceeds the number of outcomes of a pure non-degenerate measurement. Moreover, we described a procedure to amplify the dimension mismatch, leading to an arbitrary large mismatch. We then investigated the link between dimension mismatch and communication power, showing violation of information causality and the collapse of communication complexity in boxworld.
An interesting point is that we recover here previous results on the astonishing communication power in boxworld, but using a different approach. Instead of considering two observers sharing pre-established non-local correlations and sending classical communication to each other, we considered the case in which one observer sends a physical system (a hypercube bit) to the other. Hence it is the properties of a single system which are exploited here, instead of the strong non-local correlations of bipartite systems. This illustrates the strong connection that exists between the properties of the state space of a single system with the strength of non-local correlations that are obtained when looking at bipartite systems [12, 29, 30, 50]. It is important to note that, although we do not directly consider bipartite (or multipartite) systems, we did make an assumption about how single systems can be combined. Specifically, in the procedure we used to amplify dimension mismatch, it was essential to assume that systems can be combined using the maximal tensor product, which does ensure the existence of maximally non-local correlations, such as PR boxes. This shows that dimension and non-locality are connected.
Another aspect worth mentioning is that concepts of dimension discussed here allow us to characterize information processing in GPTs without introducing a notion of entropy, a notoriously problematic issue [51–53].
It would be interesting to see how general the present results are. Considering an arbitrary model featuring a dimension mismatch, can this dimension mismatch always be amplified? What are the information-theoretic properties of such a model? For instance, does a dimension mismatch always lead to a collapse of communication complexity? Another possible direction is to consider the present ideas for the problem of deriving quantum theory from a set of physically reasonable axioms [5–8, 10]. Indeed, imposing that the measurement dimension and information dimension are equal seems to have non-trivial consequences on the structure of the underlying physical theory and its information-theoretic capabilities. In order to address these questions, it would be desirable to adapt the present definitions of dimension. Specifically, instead of asking for perfect distinguishability (as we do here), one could impose a lower bound on the distinguishability of states, choosing an appropriate measure of distinguishability. Note that a recent work [56] suggested to use the mutual information in this context, proposing a principle similar to our reformulation of information causality; see equation (3). We expect such an approach to detect a considerably larger class of theories featuring a dimension mismatch.
Another direction would be to see whether the present approach is related to the principle of local orthogonality [33, 34], also referred to as the exclusivity principle [35] when discussing contextually. The main idea behind this principle is to demand the following. Consider a set of events of obtaining outcomes 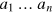 upon performing measurements
upon performing measurements 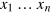 , which we denote by
, which we denote by 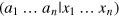 . Here we focus on sets of events where all possible pairs of events are orthogonal, i.e., mutually exclusive (at least one party performs the same measurement but obtains different outcomes). The principle then says that the sum of conditional probabilities of all events (in the set) should not exceed one. That is, events which are pairwise orthogonal are all mutually exclusive. Indeed, the notion of pairwise orthogonality that appears here is reminiscent of our definition of the information dimension, which represents the maximal number of states which are all pairwise orthogonal. We conjecture that, in a model without dimension mismatch, that is where
. Here we focus on sets of events where all possible pairs of events are orthogonal, i.e., mutually exclusive (at least one party performs the same measurement but obtains different outcomes). The principle then says that the sum of conditional probabilities of all events (in the set) should not exceed one. That is, events which are pairwise orthogonal are all mutually exclusive. Indeed, the notion of pairwise orthogonality that appears here is reminiscent of our definition of the information dimension, which represents the maximal number of states which are all pairwise orthogonal. We conjecture that, in a model without dimension mismatch, that is where 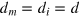 , the principle of local orthogonality should be satisfied. Consider a set of d pairwise orthogonal events, i.e., measurement outcomes or effects. Then one should be able to construct from these effects a d-outcome measurement, which is pure and non-degenerate. Indeed, such a measurement must be properly normalized, i.e., the sum of the probabilities of each outcome must be one. Hence, if such a measurement can always be constructed, it follows that local orthogonality is satisfied. It would be interesting to derive a formal proof from the above intuitive argument. The converse link also deserves attention, that is, does local orthogonality imply no dimension mismatch, i.e.,
, the principle of local orthogonality should be satisfied. Consider a set of d pairwise orthogonal events, i.e., measurement outcomes or effects. Then one should be able to construct from these effects a d-outcome measurement, which is pure and non-degenerate. Indeed, such a measurement must be properly normalized, i.e., the sum of the probabilities of each outcome must be one. Hence, if such a measurement can always be constructed, it follows that local orthogonality is satisfied. It would be interesting to derive a formal proof from the above intuitive argument. The converse link also deserves attention, that is, does local orthogonality imply no dimension mismatch, i.e., 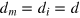 ? Note that an interesting step in this direction was recently given in [55], where it is shown that the set of 'almost quantum correlations' [54] (i.e., a superset of quantum correlations which is proven to satisfy local orthogonality and that does not allow for trivial communication complexity) will have no dimension mismatch.
? Note that an interesting step in this direction was recently given in [55], where it is shown that the set of 'almost quantum correlations' [54] (i.e., a superset of quantum correlations which is proven to satisfy local orthogonality and that does not allow for trivial communication complexity) will have no dimension mismatch.
7. Thermodynamics perspective
Finally, we believe that the present ideas also have implications from a more physical perspective, in particular for thermodynamics. The main point we would like to raise here is that a dimension mismatch may potentially lead to a violation of the second law. We formalize this question by asking if a system with a dimension mismatch, such as the hypercube bit, could lead to the realization of Maxwellʼs demon. Note that recent works have also discussed thermodynamics in the context of GPTs [39–41].
We first argue that the concept of measurement dimension is related to the cost of erasing the information encoded in a physical system. For instance, in quantum theory, the cost of erasing a qudit (a system in a Hilbert space of dimension d and a vanishing Hamiltonian) is given by 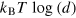 (see [38]), where T is the temperature of the external bath used to perform the erasure, and kB is the Boltzman constant. This can be done by performing an ideal and non-degenerate measurement on the system and then erasing the information about the outcome of this measurement, which costs exactly
(see [38]), where T is the temperature of the external bath used to perform the erasure, and kB is the Boltzman constant. This can be done by performing an ideal and non-degenerate measurement on the system and then erasing the information about the outcome of this measurement, which costs exactly 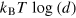 . Note that the state of the system after the measurement is one of the d pure eigenstates of the measurement. Hence, one can finally reset the system back to any desired pure state by applying a suitable unitary transformation to the system—this operation being unitary does not change the entropy of the system, and since the Hamiltonian vanishes it costs no energy.
. Note that the state of the system after the measurement is one of the d pure eigenstates of the measurement. Hence, one can finally reset the system back to any desired pure state by applying a suitable unitary transformation to the system—this operation being unitary does not change the entropy of the system, and since the Hamiltonian vanishes it costs no energy.
Following this line of reasoning, we will now argue that the cost of erasing a hypercube bit is 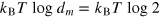 . An aspect that deserves clarification here is how one should define the post-measurement state in the case of a hypercube bit. For simplicity, let us focus on the g-bit. We assume here that the post-measurement state for measurement x = 0 is given by the pure state
. An aspect that deserves clarification here is how one should define the post-measurement state in the case of a hypercube bit. For simplicity, let us focus on the g-bit. We assume here that the post-measurement state for measurement x = 0 is given by the pure state 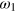 when a = 0, and
when a = 0, and 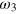 when a = 1. Similarly for measurement x = 1, we assume that the post-measurement state is
when a = 1. Similarly for measurement x = 1, we assume that the post-measurement state is 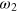 when a = 0, and
when a = 0, and 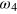 when a = 1. Indeed, this choice is somehow arbitrary, and it would be possible to define the post-measurement states differently. Nevertheless, our choice is a valid one and is consistent with the model to the best of our knowledge. Note also that when performing one measurement, say x = 0, the information about the other measurement outcome, x = 1, is erased, ensuring that only one bit of information can be retrieved by performing a measurement on the g-bit.
when a = 1. Indeed, this choice is somehow arbitrary, and it would be possible to define the post-measurement states differently. Nevertheless, our choice is a valid one and is consistent with the model to the best of our knowledge. Note also that when performing one measurement, say x = 0, the information about the other measurement outcome, x = 1, is erased, ensuring that only one bit of information can be retrieved by performing a measurement on the g-bit.
Now let us investigate the cost of erasing a g-bit. Similarly to the quantum case, one first performs a measurement, say x = 0. Then the g-bit will be found in state 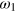 or
or 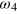 (depending on the outcome of the measurement) and can then be reset to any desired pure state by applying a suitable rotation of the square (equivalent to a unitary operation). Finally, the information about the measurement outcome must be erased, which costs
(depending on the outcome of the measurement) and can then be reset to any desired pure state by applying a suitable rotation of the square (equivalent to a unitary operation). Finally, the information about the measurement outcome must be erased, which costs 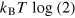 . Generalizing this procedure to hypercube bits, one thus gets that the cost of erasure of a hypercube bit is
. Generalizing this procedure to hypercube bits, one thus gets that the cost of erasure of a hypercube bit is 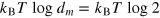 .
.
Next, one may wonder what is the significance of the information dimension in this context. It is tempting to conjecture that the information dimension captures the amount of information that the system can store, i.e, its memory size. Consider Maxwellʼs original thought experiment, in which a demon separates fast and slow particles, hence making heat flow from a cold bath into a hot one—for more details, see [37, 38]. For each incoming particle, the demon, after determining the speed of the particle, decides to let it cross the partition or not. The demon must then store this information in his memory.
Now let us imagine that the demonʼs memory is in fact a hypercube bit of dimension D (see figure 2). We denote its state as 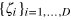 . Say the hypercube bit is initially in the state
. Say the hypercube bit is initially in the state 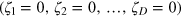 . After deciding on the fate of the first incoming particle, the demon stores the information in the hypercube bit: if he decided to let the particle pass (0), the demon leaves the state of the hypercube unchanged; but if he decides to bounce the particle back (1), he rotates the hypercube bit to the state
. After deciding on the fate of the first incoming particle, the demon stores the information in the hypercube bit: if he decided to let the particle pass (0), the demon leaves the state of the hypercube unchanged; but if he decides to bounce the particle back (1), he rotates the hypercube bit to the state 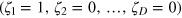 ; that is, he flips the first bit of the state. The demon then proceeds similarly for the next
; that is, he flips the first bit of the state. The demon then proceeds similarly for the next 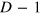 incoming particles, by updating the state of the hypercube such that the bit of information created in the kth run is stored in
incoming particles, by updating the state of the hypercube such that the bit of information created in the kth run is stored in 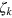 . Notice that all pure states of the hypercube-bit are assumed here to have the same energy, hence updating the state does not cost work. Moreover, note that the demon should rotate the hypercube-bit in a different direction in each step of the protocol, and erase it in the final step. He can keep track of the current step of the protocol by using a classical clock, and acting deterministically in each step.
. Notice that all pure states of the hypercube-bit are assumed here to have the same energy, hence updating the state does not cost work. Moreover, note that the demon should rotate the hypercube-bit in a different direction in each step of the protocol, and erase it in the final step. He can keep track of the current step of the protocol by using a classical clock, and acting deterministically in each step.
It thus seems that the demon can store D bits of information in the hypercube bit. After that, in order to continue sorting the particles, the demon must erase the hypercube bit, and make sure to reset it to the initial state 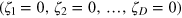 . According to Landauerʼs erasure principle [36], this operation should cost him at least
. According to Landauerʼs erasure principle [36], this operation should cost him at least 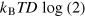 . However, we have seen above that the cost of erasing a hypercube bit (and resetting it to an arbitrary pure state) is in fact much smaller, namely
. However, we have seen above that the cost of erasing a hypercube bit (and resetting it to an arbitrary pure state) is in fact much smaller, namely  . Hence we get a contradiction with Landauerʼs principle, thus implying a violation of the second law.
. Hence we get a contradiction with Landauerʼs principle, thus implying a violation of the second law.
At this point it is legitimate, however, to question the significance of the information dimension here. In particular, one may argue that, since only one bit of information can be retrieved from the hypercube bit, the memory size of such a system is in fact 2, and not D as argued above. However, one is forced to admit that all the information about which particles the demon let pass and which ones he did not let pass is encoded in the hypercube bit, and that any single bit of this information can be retrieved at any moment. Moreover, for each new bit of information to be stored, the system is either left in the same state (if the bit to be stored has value 0) or flipped to an orthogonal state (if the bit value to be stored is 1). Another aspect that one may question is our choice of post-measurement states. In fact, one may argue that the above argument gives evidence that such a choice of post-measurement state is not a valid one. However that would imply postulating the validity of the second law (rather than deriving it), which is not desirable. An interesting question would be to revisit the above argument with other choices of post-measurement states, for instance choosing post-measurement states to be mixed ones. Could one then find a rule for choosing post-measurement states such that the second law would be satisfied in the above protocol?
While we are not in position to make a final claim at this moment, we nevertheless believe that these ideas reveal an intriguing aspect of generalized systems such as the hypercube bit. We hope that the above discussion will stimulate further work on thermodynamics in GPTs, which we feel may have impact on our understanding of quantum theory.
Acknowledgments
NB acknowledges financial support from the Swiss National Science Foundation (grant PP00P2_138917), SEFRI (COST action MP1006), and the EU DIQIP. MK acknowledges financial support from ANR retour des post-doctorants NLQCC (ANR-12-PDOC-0022-01). PS acknowledges support from the Marie Curie COFUND action through the ICFOnest program.
Footnotes
- 5
Although this may not hold in full generality, a possible alternative understanding of this definition is that dm is the number of outcomes of an ideal non-degenerate measurement. By an ideal measurement, or pure measurement, we refer to a measurement that is perfectly repeatable, i.e., when obtaining one particular outcome, repeating the measurement will always lead to the same outcome. By non-degenerate, we mean that the measurement is not coarse grained. In quantum mechanics, ideal non-degenerate measurements are rank-one projective measurements.
- 6
Note that the hypercube bits discussed here are different objects to the 'hyperbits' discussed in Pawlowski M and Winter A 2012 Phys. Rev. A 85 022331.
- 7
More formally, the set of bipartite states in the maximal tensor product can also be constructed by first defining the set of bipartite effects. The extremal bipartite effects are taken to be of the product form
 , where are extremal effects for a single system. In other words, we combine effects using the minimal tensor product. Finally, we consider all bipartite states that can be consistently defined on all these bipartite effects.
, where are extremal effects for a single system. In other words, we combine effects using the minimal tensor product. Finally, we consider all bipartite states that can be consistently defined on all these bipartite effects. - 8
Note that when including marginals, the state space features 24 pure states: (i) 16 local deterministic states and (ii) 8 non-local PR boxes (see [46] for details). However, projecting onto the correlations subspace, i.e., considering only the correlations
, the 16 deterministic states are mapped into 8 states with deterministic correlations. - 9
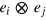
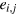
{kind=link}
{kind=link}