



Abstract
A causal scenario is a graph that describes the cause and effect relationships between all relevant variables in an experiment. A scenario is deemed 'not interesting' if there is no device-independent way to distinguish the predictions of classical physics from any generalised probabilistic theory (including quantum mechanics). Conversely, an interesting scenario is one in which there exists a gap between the predictions of different operational probabilistic theories, as occurs for example in Bell-type experiments. Henson, Lal and Pusey (HLP) recently proposed a sufficient condition for a causal scenario to not be interesting. In this paper we supplement their analysis with some new techniques and results. We first show that existing graphical techniques due to Evans can be used to confirm by inspection that many graphs are interesting without having to explicitly search for inequality violations. For three exceptional cases—the graphs numbered  in HLP—we show that there exist non-Shannon type entropic inequalities that imply these graphs are interesting. In doing so, we find that existing methods of entropic inequalities can be greatly enhanced by conditioning on the specific values of certain variables.
in HLP—we show that there exist non-Shannon type entropic inequalities that imply these graphs are interesting. In doing so, we find that existing methods of entropic inequalities can be greatly enhanced by conditioning on the specific values of certain variables.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Every physical experiment has an underlying causal structure, conceived of as a series of events, and the influences they have on each other. Just as trees look much the same when stripped of their leaves, it is possible for experimental set-ups in widely differing contexts to nevertheless exhibit the same causal structure. Causal structure is a useful abstraction that permits us to classify experiments by their cause-and-effect relationships, ignoring the unnecessary details of their physical implementation.
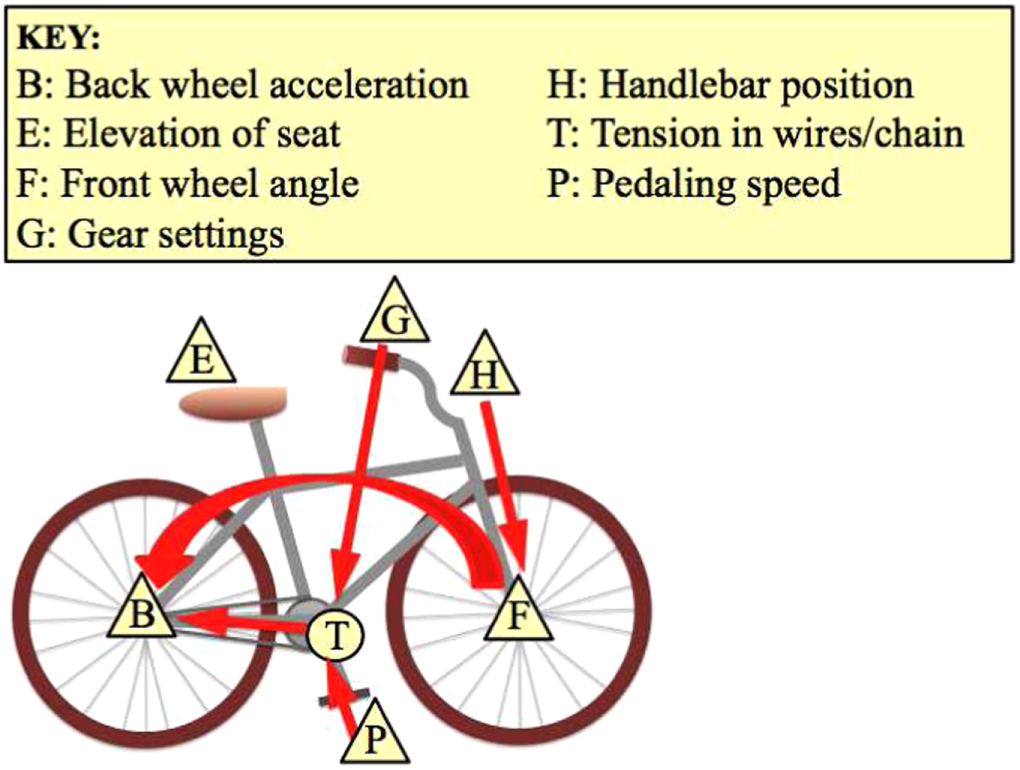
In this spirit, even a complicated physical system has a simple representation in terms of a directed acyclic graph (DAG) describing its causal structure, like that of the bicycle shown in figure 1. In this graph (called the causal graph), the triangular nodes represent the minimal set of observed events that are needed to describe the outcomes of experimental probing of the bicycle. Circular nodes represent unobserved variables, which are not directly measured but can affect the observed outcomes. The arrows indicate direct causal influences between events. The probabilities for the values of observed variables are governed by a set of functions relating each variable to its direct causes in the graph; these functions are called the model parameters. A causal graph dressed with a set of model parameters is called a causal model [1, 2].

Figure 1. A causal graph describing the functioning of a bicycle. The gear settings G (including brakes) and the pedalling speed P influence the acceleration vector B of the back wheel, via the tension T in the wire cables and in the bicycle chain. Since the tension is not directly visible to the eye, we consider it a latent variable (hence it is represented by a circular node). The handlebar position H influences the direction of B indirectly, via its influence on the front wheel orientation F. The direct influence of F on B is made possible by the frame of the bicycle. The seat elevation E is causally unrelated to the other variables, so is represented by an isolated node (such nodes are usually omitted from the graph as irrelevant).
Download figure:
Standard image High-resolution imageFollowing [3], a causal graph containing both observed and unobserved nodes is called a generalised DAG (GDAG). In general, the unobserved variables in a GDAG can represent other objects besides random variables, such as quantum states or even 'black boxes' from some hypothetical theory beyond quantum mechanics. Traditionally, however, the unobserved nodes are just random variables whose values are marginalised (summed over), in which case they are called latent variables. In this case, the causal model is called classical.
What are causal models good for? A typical scientific experiment consists of observing some phenomenon in the laboratory under controlled and repeatable conditions, and then asking whether the probability distribution of the observed events has an explanation in terms of some known physical theory. A causal model provides us with a formal definition of explanation. If we can find a causal model that reproduces the observed probabilities, then we say that the observed phenomenon can be explained by the model. Hypothesis testing then becomes the work of designing experiments to rule out different competing explanations.
The literature on causal inference provides numerous tools for deciding when one causal model is a better explanation than another. In general, simpler explanations are preferable to more complex ones. Explanations should be faithful, meaning (roughly) that the observed independencies appear in almost all causal models that have the same causal structure as the chosen explanation. If these principles are not enough to differentiate different hypotheses, it is always possible to do so by performing experimental interventions: actively changing the values of some variables and observing the reaction of the remaining variables. A tool of causal inference called the do-calculus tells us which interventions are needed to obtain specific information about the causal structure.
The question arises as to whether certain experiments in quantum physics, particularly the so-called 'Bell-type' experiments [4–6], can be explained by a causal model. It is widely agreed that any explanation of quantum phenomena in terms of a classical causal model must violate at least one of several assumptions that hold for purely classical phenomena. For example, a classical causal model can explain quantum phenomena if we allow causes to propagate faster than light, as in Bohmian mechanics [7], or if we allow measurement settings to be influenced by a hidden common cause (the super-determinism loophole), and there are many other options. A more recent perspective due to Wood and Spekkens is that classical causal explanations of quantum experiments cannot be faithful [8], i.e. the causal model is not a generic example of the set of models that share its causal structure.
An alternative to the above options is to reject classical causal models as explanations for quantum phenomena, and to seek a more general notion of a quantum causal model. Such a model would ideally provide a faithful account of quantum phenomena and enable causal inference in the quantum domain [9–13].
Going a step further, Henson, Lal and Pusey (HLP) [3] have shown that it is possible to define yet more general causal models than quantum causal models. One can consider a causal explanation in terms of any hypothetical generalised probabilistic theory (GPT), of which classical and quantum causal models are just special cases. The key to the generalisation lies in the way we interpret unobserved nodes. For a classical causal model, an unobserved node is a latent variable; in a quantum causal model, it represents a quantum resource, such as an entangled state; more generally, it represents a 'black box' resource of some GPT.
The recognition that different laws of physics necessitate different frameworks for causal inference leads to the conclusion that what constitutes an explanation depends on what model of the physical world we choose to take as primitive. It is especially interesting to ask whether, in an experiment whose causal structure is given, there exist differences between the probability distributions that can be explained by different physical models. An example is the causal structure of Bell-type experiments, shown in figure 2: if this GDAG is dressed with classical model parameters, the probability distributions satisfy Bell inequalities; if we use quantum model parameters, the distributions satisfy the weaker Tsirelson's bound [14]; and if we use a GPT that allows Popescu–Rohrlich boxes [15], the only relevant bound is the no-signalling constraint.

Figure 2. A causal graph describing a generic Bell-type experiment, in which a single source produces pairs of particles that are sent to a pair of detectors. A and B are the settings of measurements on each particle, and  are the respective outcomes. These outcomes are influenced by the unobserved node U, typically interpreted as the state of the physical particles produced by the source. This state could be a latent random variable in the classical case (like the state of the bicycle chain in figure 1), but it could also represent a quantum state or a generalised probabilistic resource like a 'PR-box' [3].
are the respective outcomes. These outcomes are influenced by the unobserved node U, typically interpreted as the state of the physical particles produced by the source. This state could be a latent random variable in the classical case (like the state of the bicycle chain in figure 1), but it could also represent a quantum state or a generalised probabilistic resource like a 'PR-box' [3].
Download figure:
Standard image High-resolution imageThe fact that this same causal graph supports different sets of observed probabilities means that experiments within this causal structure can be used to perform inference on the laws of physics themselves. In effect, by assuming that the causal structure has a given form, we are able to distinguish different physical theories within that structure. This is, after all, precisely why Bell-type experiments are commonly interpreted as ruling out classical physics (i.e. a faithful classical causal model) in favour of quantum mechanics. If a resource were ever discovered that could violate Tsirelson's bound in a Bell-type experiment, this would in turn constitute evidence against the general validity of quantum mechanics. For this reason, the causal graph of this experiment (called the Bell scenario) is considered to be 'interesting'.
Following this intuition, HLP gave a precise meaning to the term interesting as a formal property of a causal graph (we review their definition in the next section). Not every causal graph is interesting in the sense of HLP's definition. Trivial examples include DAGs in which all variables are observed (these always have a classical explanation), or GDAGs in which all variables share a single common cause (an example of superdeterminism). A less trivial example is the so-called 'one-sided Bell scenario' (see figure 3), in which one of the measurements is fixed (hence not a random variable). In this case, although there is a non-trivial no-signalling constraint imposed by the causal structure (A cannot send signals to Y), it turns out that all possible observed probability distributions can be faithfully reproduced by some choice of classical model parameters. We refer to causal structures like this one as uninteresting, because experiments based on them have no hope of differentiating between classical, quantum or supra-quantum theories.

Figure 3. A causal graph describing a 'one-sided' Bell-type experiment. Only one measurement setting A is freely chosen; the other setting is fixed to a particular value and so is not shown in the graph. The graph is uninteresting, because it allows a classical explanation regardless of the underlying physical theory. This is also true for variations of the scenario in which the value of B changes in each run but is not 'freely chosen'; see for example figure 26(a) in [8].
Download figure:
Standard image High-resolution imageThe question now arises how to decide whether a given causal graph is uninteresting or interesting. In their paper, HLP introduced a sufficient criterion for a graph to be uninteresting, and conjectured its necessity as well. To provide evidence for this conjecture, they tried to show explicitly that graphs failing their criterion must be interesting, i.e. must allow probability distributions not achievable by any classical causal model. They were able to do this for almost all graphs of up to six nodes. Only three graphs, labelled # 15, 16, 20 (see figure 7), resisted both the sufficient criterion for un-interestingness and the authors' attempts to find any interesting probability distributions on the graphs. A main result of the present paper is to resolve this impasse.
The method used by HLP to demonstrate interestingness is somewhat tedious, as it requires identifying an explicit constraint (e.g. an entropic constraint or algebraic inequality) and then showing that the constraint does not follow from the causal structure alone. Often the best way to achieve this is to find a counterexample—a distribution that violates the constraint in question while satisfying all the causal constraints—but this requires performing an explicit search of the probability space. In this paper, we show that this tedious process can sometimes be sidestepped using known techniques from the literature, which allow interestingness to be ascertained just by inspecting the graph.
Unfortunately, these techniques do not help us in the case of graphs # 15, 16, 20, and we are ultimately forced to derive a new kind of inequality for these graphs, which can then be violated by an appropriately defined probability distribution in order to establish their interestingness. Although tedious, this method reveals a new class of fine-grained inequalities of non-Shannon type. These inequalities show some promise for being generalised to more complicated scenarios.
The paper is organised as follows. Section 2 contains essential notation and background. We then show in section 3 that some simple graphical methods due to Evans [16, 17] can be used to confirm the interestingness of a graph by inspection. To illustrate the usefulness of this method, we apply it to the graphs considered by HLP and confirm their results. The only cases that do not satisfy Evan's sufficient criteria for interestingness are the Bell and Triangle scenarios, and the graphs # 15, 16, 21. For the latter three, in section 4 we propose a novel extension of the methods of entropic inequalities [18–20] that confirms these graphs as interesting (and thereby completes the establishment of HLP's conjecture for graphs with up to six nodes). Section 5 contains our conclusions and outlook.
2. Definitions and statement of the problem
In this section we review notation and definitions that will be used in this paper. We refer the reader to [1, 2] for background on causal models, and to [18–21] for background on entropic bounds for causal graphs relevant to this paper.
In this work, we are concerned with joint probability distributions  of random variables denoted by capital Roman letters
of random variables denoted by capital Roman letters  . Sets of random variables will also be denoted by capital Roman letters; the context will make it clear whether a letter refers to a single variable or a set of variables. For expressions involving set unions, we omit the '
. Sets of random variables will also be denoted by capital Roman letters; the context will make it clear whether a letter refers to a single variable or a set of variables. For expressions involving set unions, we omit the ' ', for example
', for example  is understood. Each variable takes values in a discrete, finite set. Whenever we need to make specific reference to them, we take these values to be positive integers. When talking about a specific joint probability distribution, e.g.
is understood. Each variable takes values in a discrete, finite set. Whenever we need to make specific reference to them, we take these values to be positive integers. When talking about a specific joint probability distribution, e.g.  , we will often represent the marginal distributions of P simply by omitting the relevant variables from P's domain; e.g.
, we will often represent the marginal distributions of P simply by omitting the relevant variables from P's domain; e.g.  . A conditional probability, denoted
. A conditional probability, denoted  for disjoint sets of variables
for disjoint sets of variables  , defines a family of probability distributions on the domain of X, parametrised by the discrete index Y. Thus, for example,
, defines a family of probability distributions on the domain of X, parametrised by the discrete index Y. Thus, for example,  and
and  are two different distributions of the variable X, both belonging to the parametrised family of distributions
are two different distributions of the variable X, both belonging to the parametrised family of distributions  . The law of total probability relates all these concepts in a simple equation:
. The law of total probability relates all these concepts in a simple equation:  .
.
There are two key properties of joint probability distributions that can be used to characterise them: the conditional independence (CI) relations between variables, and the entropic relations between the variables. We discuss each of these in turn.
Definition 1: CI relations. Let  be three disjoint sets of variables with joint distribution
be three disjoint sets of variables with joint distribution  . The sets
. The sets  and
and  are said to be conditionally independent given
are said to be conditionally independent given  , denoted
, denoted  , iff
, iff  .
.
Informally, this means that learning the value of Y provides no new information about the value of X if we already know the value of Z. Given a distribution P(V) on a set of variables V, the set denoted  contains all CI relations that hold in P between all disjoint subsets of V. Any set of CI relations implies further CI relations via the semi-graphoid axioms, which are in turn derivable from the axioms of probability theory. We do not reproduce these here as we will not require them explicitly. A set of CI relations is called complete iff it is closed under the semi-graphoid axioms. Unless stated otherwise, all sets of CI relations referred to in this paper are assumed to be complete.
contains all CI relations that hold in P between all disjoint subsets of V. Any set of CI relations implies further CI relations via the semi-graphoid axioms, which are in turn derivable from the axioms of probability theory. We do not reproduce these here as we will not require them explicitly. A set of CI relations is called complete iff it is closed under the semi-graphoid axioms. Unless stated otherwise, all sets of CI relations referred to in this paper are assumed to be complete.
Of particular interest are those complete sets of CI relations that can be represented by a DAG, where each node in the DAG represents a variable. Representation means that the CI relations are obtained from the graph using a criterion called d-separation:
Definition 2: d-separation. Given a DAG for a set of variables  , two disjoint subsets of variables
, two disjoint subsets of variables  and
and  are said to be d-separated by a third disjoint set
are said to be d-separated by a third disjoint set  , denoted
, denoted  , iff all undirected paths (i.e. ignoring the direction of arrows) from
, iff all undirected paths (i.e. ignoring the direction of arrows) from  to
to  are blocked by a member of
are blocked by a member of  . A path is blocked by a member of
. A path is blocked by a member of  iff:
iff:
- (i)the path contains a chain
 or a fork such that the middle node is in ; or
or a fork such that the middle node is in ; or - (ii)the path contains a collider such that the node and its descendants are not in .If a path is not blocked, it is said to be unblocked. If there is no path connecting two nodes, as in a disconnected graph, they are trivially d-separated by all other subsets of nodes.







By imposing a correspondence between d-separation and CI relations,  , every DAG G(V) implies a complete set of CI relations on the variables V, denoted
, every DAG G(V) implies a complete set of CI relations on the variables V, denoted  .
.
The link between CI relations and causal models is as follows: a causal model is regarded as a possible explanation of a distribution P(V) if the set of CI relations  obtained from the model's DAG are a subset of the set
obtained from the model's DAG are a subset of the set  . More generally, we might regard P(V) as the marginal of an unknown distribution
. More generally, we might regard P(V) as the marginal of an unknown distribution  and seek an explanation in terms of a GDAG
and seek an explanation in terms of a GDAG  that includes latent variables U. In this case consistency requires that the subset of CI relations
that includes latent variables U. In this case consistency requires that the subset of CI relations  (i.e. restricted to the observed variables V) should be a subset of the CI relations in the marginal
(i.e. restricted to the observed variables V) should be a subset of the CI relations in the marginal  .
.
Since our main goal in this work is to classify the possible distributions that can arise from a given GDAG ignoring interventions, we do not review the details of causal inference, although we refer to it in passing in section 4.
We now turn to a different property of probability distributions: the entropic constraints between variables. Given any set of variables X distributed by P(X), we can associate an entropy, H(X). A common example is the Shannon entropy [22] defined by:

where the sum is over the values of all variables in X. Given an entropy function, it is also useful to define the conditional mutual information of X and Y conditional on Z as:

Intuitively, this tells us how much the variables X and Y are correlated, conditional on the value of Z. The connection to CI relations is that the causal constraint  is equivalent to the entropic constraint
is equivalent to the entropic constraint  .
.
Unless otherwise specified, the results in this work apply to any entropy function that satisfies the polymatroidal axioms (also called elementary inequalities, these are standard in information theory—see e.g. [23]). Let V denote a set of variables,  an arbitrary subset, and
an arbitrary subset, and  specific variables in V. Then these inequalities are:
specific variables in V. Then these inequalities are:

Any inequality that follows from these is called a Shannon-type inequality. Given a set of variables V distributed by P(V), an entropy function assigns a real value  to all subsets of V. If we regard each subset as the basis of an abstract vector space, then the entropy function maps the distribution P to a vector in this space; the set of all such vectors (corresponding to valid probability distributions) defines a convex cone. An explicit characterisation of this cone has not been found to date. However, since all valid entropy functions must satisfy the inequalities (2), these define an outer approximation called the Shannon cone. The entropy vector of any valid distribution P(V) must lie within this cone, but the converse is not true—there are sometimes distributions that satisfy all Shannon-type inequalities but cannot be obtained as the marginal of a valid probability distribution on V.
to all subsets of V. If we regard each subset as the basis of an abstract vector space, then the entropy function maps the distribution P to a vector in this space; the set of all such vectors (corresponding to valid probability distributions) defines a convex cone. An explicit characterisation of this cone has not been found to date. However, since all valid entropy functions must satisfy the inequalities (2), these define an outer approximation called the Shannon cone. The entropy vector of any valid distribution P(V) must lie within this cone, but the converse is not true—there are sometimes distributions that satisfy all Shannon-type inequalities but cannot be obtained as the marginal of a valid probability distribution on V.
We are now in a position to formally state the problem of whether or not a GDAG is interesting. Let  be a GDAG with observed variables V and unobserved variables U. We are concerned with the question of whether all distributions P(V) that respect the causal structure of G can arise as the marginal distribution of a classical causal model. Following HLP, let
be a GDAG with observed variables V and unobserved variables U. We are concerned with the question of whether all distributions P(V) that respect the causal structure of G can arise as the marginal distribution of a classical causal model. Following HLP, let  be the set of distributions P(V) that respect the observable independencies implied by G, i.e. such that
be the set of distributions P(V) that respect the observable independencies implied by G, i.e. such that  . Next, define
. Next, define  as the set of distributions P(V) that are marginals of some probability distribution
as the set of distributions P(V) that are marginals of some probability distribution  having
having  . Since the latter condition is strictly stronger, we have
. Since the latter condition is strictly stronger, we have  , and the graph is called interesting if and only if the inclusion is strict,
, and the graph is called interesting if and only if the inclusion is strict,  (otherwise it is uninteresting). Note that a difference between these sets indicates the existence of constraints on
(otherwise it is uninteresting). Note that a difference between these sets indicates the existence of constraints on  that can be violated by distributions in
that can be violated by distributions in  . Thus, a sufficient condition to show that a GDAG is interesting is to identify a constraint in
. Thus, a sufficient condition to show that a GDAG is interesting is to identify a constraint in  that does not apply in
that does not apply in  . This can be established in two ways: (i) the constraint can be proven not to follow from the contraints that define the set
. This can be established in two ways: (i) the constraint can be proven not to follow from the contraints that define the set  , or (ii) the constraint can be shown to be violated by a specific distribution in
, or (ii) the constraint can be shown to be violated by a specific distribution in  . The first method is simplest (when it applies) and can be done by purely graphical techniques, some of which are reviewed in the next section. The second method requires searching the probability space of
. The first method is simplest (when it applies) and can be done by purely graphical techniques, some of which are reviewed in the next section. The second method requires searching the probability space of  for suitable counterexamples, but can succeed in many cases where the first method fails; in section 4 we employ this method using what we call 'fine grained' inequalities.
for suitable counterexamples, but can succeed in many cases where the first method fails; in section 4 we employ this method using what we call 'fine grained' inequalities.
3. The skeleton method and e-separation
In this section, we review two graphical techniques proposed by Evans for identifying cases where  , that is, for identifying graphs as interesting. The first technique is called the skeleton method, and the second is called e-separation. As we will see, these are not independent; the skeleton method derives from a corollary of e-separation and is easier to understand and use. For graphs larger than 7 nodes, however, we argue that e-separation is the more general and more useful method.
, that is, for identifying graphs as interesting. The first technique is called the skeleton method, and the second is called e-separation. As we will see, these are not independent; the skeleton method derives from a corollary of e-separation and is easier to understand and use. For graphs larger than 7 nodes, however, we argue that e-separation is the more general and more useful method.
We begin with some useful definitions adapted from [16, 17]. Where our terminology differs from that of Evans, a translation is provided in the footnotes. In what follows,  is a GDAG with observed variables V and unobserved variables U.
is a GDAG with observed variables V and unobserved variables U.
Definition 3: hidden paths and causes. Let  be any specific variables in
be any specific variables in  . A directed path from
. A directed path from  to
to  is called a
is called a  iff it contains more than one arrow and all nodes on the path besides
iff it contains more than one arrow and all nodes on the path besides  are in
are in  (i.e. unobserved). Two variables
(i.e. unobserved). Two variables  are said to share a
are said to share a  iff they share an unobserved common ancestor
iff they share an unobserved common ancestor  to which they are either directly connected, or connected by a hidden path. (Note: a variable is not considered to be an ancestor of itself). For example, in figure 4(a), the node
to which they are either directly connected, or connected by a hidden path. (Note: a variable is not considered to be an ancestor of itself). For example, in figure 4(a), the node  is a hidden common cause of the nodes
is a hidden common cause of the nodes  and
and  .
.

Figure 4. Canonical projection of a GDAG. (a) Shows the original GDAG, whose only maximal subset of size  is
is  (highlighted). (b) Is the corresponding canonical GDAG. By definition, both have the same skeleton, shown in (c). This example is taken from Evans [17].
(highlighted). (b) Is the corresponding canonical GDAG. By definition, both have the same skeleton, shown in (c). This example is taken from Evans [17].
Download figure:
Standard image High-resolution imageDefinition 4: maximal connected subsets1
. In the GDAG  , a subset of observed variables
, a subset of observed variables  is called
is called  iff all nodes in
iff all nodes in  share a single hidden common cause. A connected set
share a single hidden common cause. A connected set  is called
is called  iff there is no other connected set that fully contains it. Let
iff there is no other connected set that fully contains it. Let  denote the set of all maximal connected subsets (of size
denote the set of all maximal connected subsets (of size  ) in
) in  . For example, in figure 4(a), the sets
. For example, in figure 4(a), the sets  are connected subsets, and
are connected subsets, and  is the only non-trivial maximal connected subset.
is the only non-trivial maximal connected subset.
Definition 5: canonical GDAG2
. Given the GDAG  , define its
, define its 
 as follows:
as follows:
- (i)The observed nodes of are the same as those in .
- (ii)Two observed nodes are connected by an arrow in iff they are connected by an arrow or a hidden path in .
- (iii)There is one unobserved node in for each maximal connected subset of , and each node in is a direct cause of all nodes in the corresponding element of . Figure 4 shows an example of the canonical projection of a GDAG. A GDAG is said to be iff it is equal to its own canonical projection.











As shown by Evans (see proposition 4.9(b) and theorem 4.13 in [17]), every GDAG is observationally equivalent to its canonical projection, in the sense that they have the same set of possible marginal distributions P(V) on the observed variables.
Definition 6: GDAG skeleton. Let  be a canonical GDAG with maximal connected subsets
be a canonical GDAG with maximal connected subsets  . The
. The  of
of  is defined to be an undirected graph having nodes
is defined to be an undirected graph having nodes  , and where two nodes are connected iff they are connected by an arrow in
, and where two nodes are connected iff they are connected by an arrow in  , or belong to the same maximal connected subset in
, or belong to the same maximal connected subset in  .
.
(If G is not canonical, we define its skeleton to be the skeleton of its associated canonical GDAG). For example, figures 5(a) and (b) shows two GDAGs with their corresponding skeletons underneath. We can now introduce the skeleton method:

Figure 5. Application of the skeleton method to graph #21 from HLP. The original GDAG and its skeleton are shown in (a). Since the graph has no observable conditional independencies, a candidate for the comparison graph K is a complete graph, like the one shown in (b). Since its skeleton is different, theorem 1 implies the original graph is interesting.
Download figure:
Standard image High-resolution imageTheorem 1: The skeleton method. Consider a GDAG  . Let
. Let  be a GDAG with the same set of observable variables
be a GDAG with the same set of observable variables  and observable CI relations
and observable CI relations  , but for which it is known that
, but for which it is known that  (assuming such a GDAG can be found). Suppose furthermore that the skeletons of
(assuming such a GDAG can be found). Suppose furthermore that the skeletons of  and
and  are different. Then
are different. Then  for
for  .
.
The proof follows from proposition 6.5 in [17], which states that the observed marginals of G and K are different if they have different skeletons. Since they have the same set of observable variables and observable CI relations, the set  is the same for both graphs, and since
is the same for both graphs, and since  for K, it follows that
for K, it follows that  for G.□
for G.□
This method is useful for GDAGs having few or no observed CI relations, where a suitable GDAG K is easy to find. For instance, if  , one can always take K(V) to be a maximally connected DAG. It is likely to become increasingly difficult to find a suitable graph K with which to apply the skeleton method for large numbers of variables; nevertheless the method works well for small GDAGs. Figure 5 shows how it can be applied to graph #21 from [3], and the reader is encouraged to verify that the same method can be used to establish the interestingness of most of the other graphs considered by those authors. The notable exceptions are #2 (the Bell scenario), #8 (the Triangle scenario), and #15,16, 20 which we consider in section 4. For the Bell scenario, the method fails because there is no graph K that satisfies the no-signalling constraint and has
, one can always take K(V) to be a maximally connected DAG. It is likely to become increasingly difficult to find a suitable graph K with which to apply the skeleton method for large numbers of variables; nevertheless the method works well for small GDAGs. Figure 5 shows how it can be applied to graph #21 from [3], and the reader is encouraged to verify that the same method can be used to establish the interestingness of most of the other graphs considered by those authors. The notable exceptions are #2 (the Bell scenario), #8 (the Triangle scenario), and #15,16, 20 which we consider in section 4. For the Bell scenario, the method fails because there is no graph K that satisfies the no-signalling constraint and has  , while for the Triangle scenario it fails because the skeleton of all candidate K graphs is the same as that of G. For #15,16, 20, the situation is analagous to the Bell scenario: for each one, there is no graph K that satisfies the same observed CI relations yet has a different skeleton.
, while for the Triangle scenario it fails because the skeleton of all candidate K graphs is the same as that of G. For #15,16, 20, the situation is analagous to the Bell scenario: for each one, there is no graph K that satisfies the same observed CI relations yet has a different skeleton.
We now discuss a second graphical method based on the idea of 'extended d-separation', or e-separation in Evans [16].
Definition 7: e-separation. Let  be four disjoint sets of variables in a DAG. Suppose that, after removing the nodes
be four disjoint sets of variables in a DAG. Suppose that, after removing the nodes  from the graph, the sets
from the graph, the sets  and
and  are d-separated by the set
are d-separated by the set  in the new graph. Then we say that '
in the new graph. Then we say that ' '.
'.
In the above definition, the new graph produced 'after removal of the nodes W' is to be understood formally as the induced subgraph of the original graph on the complement of W, that is, the graph consisting of the nodes not in W, and the edges connecting these nodes that do not have endpoints in W.
Notice that e-separation is a relation between four sets of nodes, and it reduces to the three-set criterion of d-separation when  . Evans showed that, under certain conditions, e-separation implies an extra constraint on the set of observed classical distributions
. Evans showed that, under certain conditions, e-separation implies an extra constraint on the set of observed classical distributions  . To explain this constraint, we need one more definition:
. To explain this constraint, we need one more definition:
Definition 8: compatibility along a section. Let  and
and  be two different probability distributions on the same set of variables. If they take the same values whenever the variables
be two different probability distributions on the same set of variables. If they take the same values whenever the variables  are fixed to a particular set of values
are fixed to a particular set of values  (i.e. if
(i.e. if  ) then we say that
) then we say that  and
and  .
.
We can now describe the constraint that is implied by e-separation:
Theorem 9: e-separation constraint. Let  be any distribution in
be any distribution in  for a DAG
for a DAG  . Suppose that
. Suppose that  and
and  are e-separated by
are e-separated by  after deletion of
after deletion of  , and that no member of
, and that no member of  is descended from
is descended from  . Then for each possible value
. Then for each possible value  of
of  , the conditional distribution
, the conditional distribution  must be compatible along the section
must be compatible along the section  with a distribution
with a distribution  in which
in which  holds.
holds.
The proof of this constraint on  is derived in theorem 4.2 in [16]. The question remains under what circumstances it represents a constraint on
is derived in theorem 4.2 in [16]. The question remains under what circumstances it represents a constraint on  as well. To answer this, we require the following lemma:
as well. To answer this, we require the following lemma:
Lemma 2: Conditions for e-separation to imply.  . Let
. Let  be a GDAG in which
be a GDAG in which  are disjoint subsets of observed nodes, such that no member of
are disjoint subsets of observed nodes, such that no member of  is descended from
is descended from  and
and  and
and  are e-separated by
are e-separated by  after deletion of
after deletion of  . Then
. Then  for
for  if and only if the observed CI relations
if and only if the observed CI relations  exclude all relations of the form
exclude all relations of the form  , where
, where  is any subset of
is any subset of  .
.
Proof. First, we prove the 'only if' clause by showing that if any relation  does hold, then the e-separation constraint follows from the constraints
does hold, then the e-separation constraint follows from the constraints  alone. Let
alone. Let  , and let W take possible values
, and let W take possible values  . Suppose that
. Suppose that  holds in
holds in  . For each
. For each  we can then define
we can then define  . Since
. Since  necessarily holds in P,
necessarily holds in P,  necessarily holds in
necessarily holds in  . Moreover, each
. Moreover, each  satisfies
satisfies

hence  is compatible with P along the section
is compatible with P along the section  after conditioning on Z. Therefore, the presence of
after conditioning on Z. Therefore, the presence of  in
in  is sufficient to imply the e-separation constraint of theorem 9.
is sufficient to imply the e-separation constraint of theorem 9.
Next, we prove the 'if' clause by explicitly constructing a distribution  that satisfies
that satisfies  (and is therefore in
(and is therefore in  ) but cannot satisfy the e-separation constraint. Consider the distribution
) but cannot satisfy the e-separation constraint. Consider the distribution  in which
in which  are perfectly correlated (and take more than one value) and every other variable is fixed to a single value. (Note that this distribution is only possible if
are perfectly correlated (and take more than one value) and every other variable is fixed to a single value. (Note that this distribution is only possible if  excludes all relations of the form
excludes all relations of the form  , otherwise it is not a valid distribution for the GDAG G.) We then find that there is only a single pair of values
, otherwise it is not a valid distribution for the GDAG G.) We then find that there is only a single pair of values  for which
for which  is non-vanishing, which means that
is non-vanishing, which means that  is equal to its own 'section',
is equal to its own 'section',  . Moreover, the only normalised probability distribution that is compatible with
. Moreover, the only normalised probability distribution that is compatible with  along this section is
along this section is  itself, hence we must have
itself, hence we must have  . But this means
. But this means  are necessarily correlated in
are necessarily correlated in  conditional on Z, so the e-separation constraint is impossible to satisfy for the distribution
conditional on Z, so the e-separation constraint is impossible to satisfy for the distribution  . □
. □
These observations mean that, for a given graph, we can tell whether the e-separation constraint holds in  or not, and hence whether a graph is interesting:
or not, and hence whether a graph is interesting:
Theorem 3. The e-separation method. Consider a GDAG  with observed CI relations
with observed CI relations  . Let
. Let  be disjoint sets of observable nodes, such that no member of
be disjoint sets of observable nodes, such that no member of  is descended from
is descended from  in the graph. Then if
in the graph. Then if  and
and  are e-separated by
are e-separated by  after deletion of
after deletion of  , and if
, and if  excludes
excludes  for all subsets
for all subsets  , then
, then  for
for  .
.
The proof follows from theorem 4.2 in [16], and our lemma 2. Note that in the cases where  , the lemma also tells us how to explicitly construct a distribution that violates the e-separation constraint: simply have
, the lemma also tells us how to explicitly construct a distribution that violates the e-separation constraint: simply have  perfectly correlated and all other variables fixed.
perfectly correlated and all other variables fixed.
Figure 6 shows how to apply the e-separation method to GDAG # 17. In this graph,  correspond respectively to the sets
correspond respectively to the sets  in theorem 3, and F and D are e-separated by C after deletion of E. This means
in theorem 3, and F and D are e-separated by C after deletion of E. This means  holds in the graph after deletion, figure 6(b), but notice that neither
holds in the graph after deletion, figure 6(b), but notice that neither  nor
nor  holds in the original graph figure 6 (a). (To see this, observe that the path
holds in the original graph figure 6 (a). (To see this, observe that the path  is unblocked if we condition only on C, but if we condition on both C and E, then another path
is unblocked if we condition only on C, but if we condition on both C and E, then another path  becomes unblocked.) Hence the conditions of theorem 3 are met and the graph must be interesting.
becomes unblocked.) Hence the conditions of theorem 3 are met and the graph must be interesting.

Figure 6. Application of the e-separation method to graph #17 from HLP. The original GDAG is shown in (a), while (b) shows the GDAG after deleting E and its edges. Note that C is not descended from E; also the CI relation  holds in (b) but neither it nor
holds in (b) but neither it nor  holds in
holds in  . Theorem 3 can then be applied to show the graph is interesting, if we identify
. Theorem 3 can then be applied to show the graph is interesting, if we identify  respectively with the sets
respectively with the sets  in the Theorem.
in the Theorem.
Download figure:
Standard image High-resolution image
Figure 7. The causal graphs #15,16, 20 from HLP, with observed CI relations written below. These do not satisfy HLPs' sufficient condition for uninterestingness, but they also resist Evans' sufficient criteria for interestingness. We find a probability distribution that violates the 'fine-grained' entropic inequality (4), thereby confirming that these graphs are indeed interesting.
Download figure:
Standard image High-resolution imageNote that instead of  , we could alternatively have used the CI relation
, we could alternatively have used the CI relation  , i.e. taking the conditioned set Z to be the empty set. On the other hand, we could not have deleted C and used the resulting relation
, i.e. taking the conditioned set Z to be the empty set. On the other hand, we could not have deleted C and used the resulting relation  to invoke e-separation, because E is descended from C, violating a premise of theorem 3.
to invoke e-separation, because E is descended from C, violating a premise of theorem 3.
The e-separation method is based on theorem 4.2 in [16], of which proposition 6.5 in [17] (the basis for the skeleton method) is a corollary. We therefore expect the e-separation method to succeed in at least those cases where the skeleton method succeeded (and possibly more). In the
For GDAGs of up to six nodes, we find the e-separation method has the same success as the skeleton method: the reader is encouraged to verify that it confirms the interestingness of all GDAGs considered by HLP except the Bell scenario, the Triangle scenario, and the three GDAGs #15,16, 20.
It fails for the Bell scenario because there is no way to delete any observed nodes to create a CI relation that is not already implied by  . The Triangle scenario has a similar problem: to avoid triviality, one can only delete a single node, but then the remaining two nodes will still be correlated, i.e. no new observable CI relations are implied. The method fails for graphs # 15,16, 20, because the only viable candidates for the sets
. The Triangle scenario has a similar problem: to avoid triviality, one can only delete a single node, but then the remaining two nodes will still be correlated, i.e. no new observable CI relations are implied. The method fails for graphs # 15,16, 20, because the only viable candidates for the sets  in theorem 3 either cannot be d-separated by the deletion of other observed nodes (as in # 16), or the deletion of any candidate node does not result in new CI relations (as in # 15, 20).
in theorem 3 either cannot be d-separated by the deletion of other observed nodes (as in # 16), or the deletion of any candidate node does not result in new CI relations (as in # 15, 20).
Remark 1. In the cases of up to six nodes where the technique does work, the distribution that violates the e-separation constraint is the same distribution that HLP found to violate a relevant Shannon-type entropic inequality. This indicates that whenever the e-separation constraint applies, there may exist a corresponding Shannon-type entropic inequality.
Remark 2. In the
4. Entropic inequalities via 'fine-graining'
We now turn to the problem of establishing the interestingness of the graphs # 15,16, 20 as conjectured in HLP (these are displayed in figure 7).
Let us concentrate on graph  the others will follow in kind. For simplicity, we assume A is binary and takes values in
the others will follow in kind. For simplicity, we assume A is binary and takes values in  . Our goal is to demonstrate that the observed marginal of this graph is subject to an entropic constraint, namely:
. Our goal is to demonstrate that the observed marginal of this graph is subject to an entropic constraint, namely:

where the notation  means
means  , i.e. 'intervene on A and set it to 0' . Thus, for example,
, i.e. 'intervene on A and set it to 0' . Thus, for example,  is the mutual information of
is the mutual information of  in the post-intervention distribution
in the post-intervention distribution  . The reader might object that, if we cannot perform interventions, then we cannot obtain the quantities appearing on the left hand side of the inequality (4). In fact, we can obtain these quantities without doing an intervention, because A is an exogenous node in the graph (it has no parents). Hence the following identity holds:
. The reader might object that, if we cannot perform interventions, then we cannot obtain the quantities appearing on the left hand side of the inequality (4). In fact, we can obtain these quantities without doing an intervention, because A is an exogenous node in the graph (it has no parents). Hence the following identity holds:

where  is a Kronecker delta function. Intuitively, this says that the post-intervention distribution is the same as the distribution obtained by post-selecting on A having the particular value 0 or 1. We therefore have a situation where the causal graph allows us to learn something about the post-intervention distributions without actually performing an intervention. Whenever a constraint such as the inequality (4) involves these post-intervention distributions, we call it a fine-grained constraint. We now establish a general framework for obtaining fine-grained entropic constraints from a causal graph, and use it to derive equation (4).
is a Kronecker delta function. Intuitively, this says that the post-intervention distribution is the same as the distribution obtained by post-selecting on A having the particular value 0 or 1. We therefore have a situation where the causal graph allows us to learn something about the post-intervention distributions without actually performing an intervention. Whenever a constraint such as the inequality (4) involves these post-intervention distributions, we call it a fine-grained constraint. We now establish a general framework for obtaining fine-grained entropic constraints from a causal graph, and use it to derive equation (4).
4.1. Preliminaries
Let  be a classical distribution (all variables are observed) compatible with some DAG
be a classical distribution (all variables are observed) compatible with some DAG  in the usual sense that
in the usual sense that  . Here,
. Here,  are specific variables, R is the set of remaining variables, and Z is exogenous. Then the distribution factorises as
are specific variables, R is the set of remaining variables, and Z is exogenous. Then the distribution factorises as  . In the following we assume Z is binary for clarity, but the results can easily be extended to the case where Z is an arbitrary discrete variable. We give definitions for the case Z = 0; similar definitions are understood to hold for Z = 1.
. In the following we assume Z is binary for clarity, but the results can easily be extended to the case where Z is an arbitrary discrete variable. We give definitions for the case Z = 0; similar definitions are understood to hold for Z = 1.
Define the notation:

Therefore,

For any subset of variables S (excluding Z), we define  as the entropy of S with respect to the post-intervention distribution
as the entropy of S with respect to the post-intervention distribution  :
:

Entropies of this form (pertaining to a specific value of Z) are called 'fine-grained'. Functions of the entropies, like the mutual information  , are defined analogously, using the entropies of the post-intervention distribution. For example:
, are defined analogously, using the entropies of the post-intervention distribution. For example:

Any inequality that contains terms like these is said to be 'fine-grained'. Any CI relations that hold in the original distribution necessarily hold in the post-intervention distribution. For example, if  holds in
holds in  , then the statement
, then the statement  is also valid. Moreover, we have:
is also valid. Moreover, we have:
Corollary 4. If  holds in
holds in  , then
, then  .
.
This statement is a consequence of rule 3 in Pearl's do calculus (see Pearl [1], theorem 3.4.1). It is important because it allows us to relate the entropies of distributions for which Z = 0 to entropies of distributions in which Z = 1, which implies fine-grained entropic constraints. In what follows, we only make use of corollary 4, but in general the entire do calculus is available for deriving such constraints. We return to this point in section 4.3.
4.2. Derivation of the inequality
Returning to the specific case of graph  , we aim to prove equation (4). To this end we require the following elementary entropic inequalities:
, we aim to prove equation (4). To this end we require the following elementary entropic inequalities:





as well as the CI relations:




which happen to hold in all three graphs. It is useful to define the quantities:

so that the lhs of (4) can be written (after expanding and cancelling some terms) as:


and from (10) we obtain:

Similarly, from (13) and (16), and from (12) we obtain:

It follows that:

But (17) implies:

so the upper bounds simplify to:

Combining these with (19), we find the lhs of (4) is upper bounded by:

Finally, using (14) and (18), this simplifies to:

where in the last step we used the elementary inequality  . This completes the proof of (4).□
. This completes the proof of (4).□
It follows that the entropic inequality (4) holds in graph  in fact, since the CI relations used in the proof are common to all three DAGs, the same inequality can be shown to hold in all three. Furthermore, we now present a probability distribution on the observed variables that satisfies all the observed CI relations of both
in fact, since the CI relations used in the proof are common to all three DAGs, the same inequality can be shown to hold in all three. Furthermore, we now present a probability distribution on the observed variables that satisfies all the observed CI relations of both  but violates this inequality. Let
but violates this inequality. Let  be an observed marginal distribution having the special property that when A = 0, the bits
be an observed marginal distribution having the special property that when A = 0, the bits  are perfectly correlated and F is fixed to 0, whereas when A = 1 the bits
are perfectly correlated and F is fixed to 0, whereas when A = 1 the bits  are correlated and E is fixed. More formally,
are correlated and E is fixed. More formally,  satisfies:
satisfies:
- (i)all variables are binary with values in
- (ii)the bits A and D are random and evenly distributed;
- (iii) ;
- (iv),



where ⊕ is addition modulo 2, and A × D means the product of the values of  . Although
. Although  satisfies all of the CI relations required by the DAGs
satisfies all of the CI relations required by the DAGs  for the observed variables, it violates the constraint equation (4), since (using the Shannon entropy) the lhs evaluates to 2, whereas the bound H(D) for a binary variable D is only 1. Hence
for the observed variables, it violates the constraint equation (4), since (using the Shannon entropy) the lhs evaluates to 2, whereas the bound H(D) for a binary variable D is only 1. Hence  cannot be a (classical) marginal of the underlying DAG. The existence of this distribution therefore establishes
cannot be a (classical) marginal of the underlying DAG. The existence of this distribution therefore establishes  for #15, 16.
for #15, 16.
The case of  requires a little more care, because the distribution
requires a little more care, because the distribution  does not satisfy the relation
does not satisfy the relation  , which holds in
, which holds in  . Fortunately, a minor adjustment of
. Fortunately, a minor adjustment of  will allow us to obtain a distribution which does the job. Consider a distribution in which we allow E to take three possible values,
will allow us to obtain a distribution which does the job. Consider a distribution in which we allow E to take three possible values,  , but all other variables remain binary. Define the distribution
, but all other variables remain binary. Define the distribution  by the following property: when A = 0, the bits
by the following property: when A = 0, the bits  are perfectly correlated and have values in
are perfectly correlated and have values in  , while F is fixed to 0; when A = 1 the bits
, while F is fixed to 0; when A = 1 the bits  are perfectly correlated and E is fixed to the value 2. Formally:
are perfectly correlated and E is fixed to the value 2. Formally:
- (i), ;
- (ii)the bits A and D are random and evenly distributed;
- (iii) ;
- (iv) ,




(note that the second plus sign in (iv) is not modulo 2). This distribution is almost identical to the previous one, except that knowledge of the value of E is now sufficient to deduce the value of A. This means the distribution additionally satisfies  , and therefore satisfies all the observed CI relations of
, and therefore satisfies all the observed CI relations of  . As before, this distribution achieves 2 on the lhs and 1 on the rhs of equation (4), violating the inequality.
. As before, this distribution achieves 2 on the lhs and 1 on the rhs of equation (4), violating the inequality.
Remark. One could of course have used  to violate the inequality for all three graphs (since it satisfies the CI relations of all three), eliminating the need for
to violate the inequality for all three graphs (since it satisfies the CI relations of all three), eliminating the need for  however, we have chosen to include the latter distribution in our discussion because, while its scope is more limited, it is simpler in that it uses only binary variables.
however, we have chosen to include the latter distribution in our discussion because, while its scope is more limited, it is simpler in that it uses only binary variables.
In conclusion, the above distributions  satisfy the observed CI relations of
satisfy the observed CI relations of  , and
, and  , respectively, but violate the inequality equation (4) that holds in these graphs, establishing
, respectively, but violate the inequality equation (4) that holds in these graphs, establishing  . This completes the missing piece of HLP's analysis of DAGs of up to six nodes.
. This completes the missing piece of HLP's analysis of DAGs of up to six nodes.
4.3. Discussion
The previous section suggests a general approach to finding fine-grained entropic inequalities such as equation (4). One first selects one or more exogenous nodes to be 'fine-grained', which means that we specify the set of possible values of each of these variables (e.g. that they are binary and take values in  ). We then consider the entropic inequalities conditioned on specific values of the fine-grained nodes (i.e. the fine-grained versions of the usual entropic inequalities). Corollary 4, together with the CI relations from the graph, implies constraints relating entropies that are fine-grained on different values of the same variable. These constraints take the form of inequalities like equation (4). The usual methods for finding entropic inequalities apply—the only difference is that the set of inequalities is enlarged to include fine-grained entropies as well as normal entropies.
). We then consider the entropic inequalities conditioned on specific values of the fine-grained nodes (i.e. the fine-grained versions of the usual entropic inequalities). Corollary 4, together with the CI relations from the graph, implies constraints relating entropies that are fine-grained on different values of the same variable. These constraints take the form of inequalities like equation (4). The usual methods for finding entropic inequalities apply—the only difference is that the set of inequalities is enlarged to include fine-grained entropies as well as normal entropies.
The method we employed in the previous section has the disadvantage that it still involves finding explicit inequalities and searching for a distribution that violates one of them. Fortunately, Wolfe et al recently proposed a convenient graphical method called the inflation DAG technique, with which they were independently able to establish the interestingness of GDAG  , as well as the Triangle and Bell scenarios [24].
, as well as the Triangle and Bell scenarios [24].
The distribution  described in the previous section is notable because it does not violate any standard Shannon-type entropic inequalities. In fact, the distribution lies inside an inner approximation of the entropy cone for scenario
described in the previous section is notable because it does not violate any standard Shannon-type entropic inequalities. In fact, the distribution lies inside an inner approximation of the entropy cone for scenario  (the author thanks Weilenmann and Colbeck for this information [25]). This means that no conventional entropic inequality can distinguish it from a valid distribution for this scenario. We conclude that fine-grained inequalities are strictly more powerful than conventional entropic inequalities.
(the author thanks Weilenmann and Colbeck for this information [25]). This means that no conventional entropic inequality can distinguish it from a valid distribution for this scenario. We conclude that fine-grained inequalities are strictly more powerful than conventional entropic inequalities.
An interesting feature of graph  is that if we make A into an unobserved variable, we recover the Triangle scenario. It turns out that the marginal obtained by summing over A in
is that if we make A into an unobserved variable, we recover the Triangle scenario. It turns out that the marginal obtained by summing over A in  is also incompatible with the Triangle scenario [24]. This suggests that although the 'W-distribution' discussed in [24] lies inside an inner approximation of the entropic cone for the Triangle scenario, it might be possible to distinguish it from a valid distribution using a fine-grained entropic inequality. However, since all observed variables in that scenario have parents, this would require an extension of the present formalism to non-exogenous nodes.
is also incompatible with the Triangle scenario [24]. This suggests that although the 'W-distribution' discussed in [24] lies inside an inner approximation of the entropic cone for the Triangle scenario, it might be possible to distinguish it from a valid distribution using a fine-grained entropic inequality. However, since all observed variables in that scenario have parents, this would require an extension of the present formalism to non-exogenous nodes.
From the presentation given here, there seem to be two obvious ways to extend the approach. The first method is to consider fine-graining by post-selecting on the values of non-exogenous nodes. For example, we could consider the distribution  obtained from
obtained from  by post-selecting on the outcome Z = 0. In the case where Z has parents in the DAG, the resulting distribution is:
by post-selecting on the outcome Z = 0. In the case where Z has parents in the DAG, the resulting distribution is:

i.e. the distribution of  conditional on Z = 0. This can be thought of as a generalisation of the rhs of equation (7) because it reduces to the same expression in the case that Z is exogenous. We could then search for fine-grained entropic inequalities conditioned on the values of non-exogenous nodes.
conditional on Z = 0. This can be thought of as a generalisation of the rhs of equation (7) because it reduces to the same expression in the case that Z is exogenous. We could then search for fine-grained entropic inequalities conditioned on the values of non-exogenous nodes.
Note that, in general, the post-selected distribution  is not the same as the post-intervention distribution
is not the same as the post-intervention distribution  . This brings us to the second possible extension, already hinted at earlier in the paper: to use post-intervention distributions like
. This brings us to the second possible extension, already hinted at earlier in the paper: to use post-intervention distributions like  in situations where Z is not exogenous. One could then make use of the full do calculus in order to discover new fine-grained entropic inequalities. We leave it to future work to explore the potential of these extensions of the fine-graining method.
in situations where Z is not exogenous. One could then make use of the full do calculus in order to discover new fine-grained entropic inequalities. We leave it to future work to explore the potential of these extensions of the fine-graining method.
5. Conclusions
The experimentally observed violation of Bell inequalities brings home the remarkable fact that, if we are certain that we know the causal structure of an experimental set-up, we can use it to make inferences about the fundamental laws of physics that govern the systems in the experiment. In particular, Bell-type experiments leverage the causal structure of space-time to rule out any faithful classical causal explanation of the experimental data. More generally, it would be useful to know which causal structures (represented by an associated GDAG) can be utilised for this purpose.
As pointed out in HLP, a necessary first step is the ability to identify the uninteresting graphs, which cannot be used for distinguishing physical theories. Whereas HLP provided a sufficient condition for uninterestingness, in this paper we drew attention to some necessary conditions due to Evans (namely, we pointed out that a graph must be interesting if it violates Evans' graphical criteria reviewed in section 3). Furthermore, we derived a fine-grained entropic inequality that is able to confirm the interestingness of graphs #15,16, 20. Inequalities of this type were shown to follow from Pearl's do calculus of interventions, suggesting the possibility of a general method for deriving such inequalities in more complicated scenarios.
Acknowledgments
The author thanks Matt Pusey, Robin J Evans, Elie Wolfe, Rafael Chaves and an anonymous referee for suggestions that greatly improved this paper. This work has been supported by the European Commission Project RAQUEL, the John Templeton Foundation, FQXi, and the Austrian Science Fund (FWF) through CoQuS, SFB FoQuS, and the Individual Project 2462.
Appendix.: e-separation versus the skeleton method
In section 3, it was claimed that a GDAG exists in which e-separation could be used to determine  , but for which the skeleton method could not be used. Here, we describe the GDAG and justify the claim. The GDAG is shown in figure A1, and its skeleton in figure A2. The three CI relations listed in figure A1 are a generating set for the observed CI relations
, but for which the skeleton method could not be used. Here, we describe the GDAG and justify the claim. The GDAG is shown in figure A1, and its skeleton in figure A2. The three CI relations listed in figure A1 are a generating set for the observed CI relations  where
where  . The variables
. The variables  are unobserved.
are unobserved.

Figure A1. A graph G that is shown to be interesting via the e-separation method, but to which one cannot apply the skeleton method. The CI relations in the box generate all relevant observed CI relations.
Download figure:
Standard image High-resolution image
Figure A2. The skeleton of the graph in figure A1.
Download figure:
Standard image High-resolution imageTo begin, let us determine that the graph G is interesting, according to the criteria of e-separation. Following theorem 3, let the sets  in the theorem correspond to
in the theorem correspond to  respectively in the graph. One can check that X and Y are e-separated by Z after deletion of W; Z is descended from W; and neither
respectively in the graph. One can check that X and Y are e-separated by Z after deletion of W; Z is descended from W; and neither  nor
nor  is implied by G (using the rules of d-separation). Thus, from lemma 2 we have
is implied by G (using the rules of d-separation). Thus, from lemma 2 we have  for G.
for G.
Next, we show that the skeleton method cannot be used to reach the same conclusion. Specifically, we show that there is no GDAG K whose skeleton is different to that of G (as displayed in figure A2) and which satisfies the same observed CI relations as G. First, we observe that any candidate GDAG K cannot have chords in its skeleton connecting the following pairs of nodes: 

 (Z, A). This is because the presence of any one of these chords would violate an observed CI relation in all GDAGs consistent with the skeleton. For example, the chord (X, Y) implies that any GDAG with that skeleton must have either a direct cause between
(Z, A). This is because the presence of any one of these chords would violate an observed CI relation in all GDAGs consistent with the skeleton. For example, the chord (X, Y) implies that any GDAG with that skeleton must have either a direct cause between  or else the two must share a hidden common cause; this means they cannot then be rendered independent by conditioning on other variables, violating
or else the two must share a hidden common cause; this means they cannot then be rendered independent by conditioning on other variables, violating  . After eliminating these chords from the skeleton, the remaining chords are
. After eliminating these chords from the skeleton, the remaining chords are 



 (Y,W). These chords are all present in the skeleton of G, shown in figure A2, hence any candidate GDAG K, to be useful for the skeleton method, must possess only a strict subset of these chords in its skeleton.
(Y,W). These chords are all present in the skeleton of G, shown in figure A2, hence any candidate GDAG K, to be useful for the skeleton method, must possess only a strict subset of these chords in its skeleton.
We now show that removing any one of the chords in G's skeleton necessarily introduces a new CI relation not implied by G. To show this, we make use of the d-separation criterion for whether a path through the graph is 'unblocked' or 'blocked' (recall definition 2). We treat each chord in turn.
Delete (X, Z): Removing this chord makes X an isolated variable. Thus, e.g.  must hold, but this is not implied by G. □
must hold, but this is not implied by G. □
Delete (Z, Y): Removing this chord leaves only one path between X and W, namely  . In order for the observed CI relation
. In order for the observed CI relation  to hold, Z must be a collider on this path. But then all paths connecting X to Y would be blocked, implying
to hold, Z must be a collider on this path. But then all paths connecting X to Y would be blocked, implying  , which is not implied by G.□
, which is not implied by G.□
Delete (Z, W): Removing this chord leaves only one path connecting X to Y, namely  . This path cannot be blocked by A. That means
. This path cannot be blocked by A. That means  only holds if
only holds if  holds—but while the former relation is implied by G, the latter is not.□
holds—but while the former relation is implied by G, the latter is not.□
Delete (A, Y): Removing this chord means that no paths connecting X and Y contain A, so these paths cannot be blocked by A. Thus, as in the previous case,  requires
requires  to hold, but this is not the case in G.□
to hold, but this is not the case in G.□
Delete (A, W): Removing this chord again leaves no path between X and Y that contains A; thus, as in the previous two cases,  cannot hold without
cannot hold without  , but only the former of the two is implied by G. □
, but only the former of the two is implied by G. □
Delete (Y, W): This case is more complicated. First, it will be useful to establish that there is a directed path from Z to Y that does not contain any other observed nodes, and in addition  do not share a hidden common cause. We will indicate this by the shorthand
do not share a hidden common cause. We will indicate this by the shorthand  (abusing notation). To prove this, note that
(abusing notation). To prove this, note that  (which is implied by G) means that all paths between X and Y are blocked by
(which is implied by G) means that all paths between X and Y are blocked by  . Since the path
. Since the path  only contains Z, this path must be blocked by Z. This can only occur if either
only contains Z, this path must be blocked by Z. This can only occur if either  , or
, or  , or both. However, the former can't be the case, since then the path
, or both. However, the former can't be the case, since then the path  would be unblocked, violating
would be unblocked, violating  , which is implied by G. So it must be the latter case:
, which is implied by G. So it must be the latter case:  .
.
Now, if we remove the chord (Y, W), there are only two paths connecting Y and W, namely  and
and  . In order to avoid
. In order to avoid  , which is not implied by G, we require that at least one of these paths is unblocked conditional on AZ, hence that A and/or Z must be a collider on its respective path. Since we have established
, which is not implied by G, we require that at least one of these paths is unblocked conditional on AZ, hence that A and/or Z must be a collider on its respective path. Since we have established  , Z cannot be a collider on the path
, Z cannot be a collider on the path  . That leaves A, but if A is a collider on
. That leaves A, but if A is a collider on  , then conditioning on A cannot block any path between X and Y. But then we are in the same position as the previous three cases: since
, then conditioning on A cannot block any path between X and Y. But then we are in the same position as the previous three cases: since  holds in G, so should
holds in G, so should  , but the latter is not implied by G.□
, but the latter is not implied by G.□
We have seen that no single chord can be removed from the skeleton of G without introducing new constraints not implied by G. However, since a CI relation cannot be invalidated by deleting further nodes or edges from a graph, it follows that the removal of any set of chords from the skeleton of G will result in new CI relations not implied by G. Together with the fact (proven above) that no chords can be added, we conclude that the skeleton of G is the only one that supports the exact set of observed CI relations  . Hence there is no GDAG K that can be used for the purposes of the skeleton method. The GDAG of figure A1 is therefore a counterexample to the proposition that the power of e-separation is the same as the skeleton method—it shows that the former method is strictly more powerful in GDAGs of eight nodes or more. (Whether a counterexample exists with only seven nodes is an open problem, but I suspect the answer is negative.)
. Hence there is no GDAG K that can be used for the purposes of the skeleton method. The GDAG of figure A1 is therefore a counterexample to the proposition that the power of e-separation is the same as the skeleton method—it shows that the former method is strictly more powerful in GDAGs of eight nodes or more. (Whether a counterexample exists with only seven nodes is an open problem, but I suspect the answer is negative.)
Footnotes
- 1
Our connected subsets are Evans' bidirected faces. Our maximal connected subsets are his bidirected facets. Our set
is Evans' set . Compare to Evans [17]. - 2
Our procedure of canonical projection is, in Evan's language, equivalent to taking the canonical DAG of the latent projection over the unobserved nodes of the original GDAG.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}